大语言模型将如何影响软件开发?
当人人具备编写代码的能力之后,这将会给软件生产和分配带来哪些结构性的变化?原文链接:https://www.geoffreylitt.com/2023/03/25/llm-end-user-programming.html未经授权,禁止转载!作者|Geoffrey Litt译者|弯月责编 |王子彧出品 | CSDN(ID:CSDNnews)近段时间,大语言模型掀起了一股狂潮。 Op...

当人人具备编写代码的能力之后,这将会给软件生产和分配带来哪些结构性的变化?
原文链接:https://www.geoffreylitt.com/2023/03/25/llm-end-user-programming.html
未经授权,禁止转载!
作者 | Geoffrey Litt 译者 | 弯月
责编 | 王子彧
出品 | CSDN(ID:CSDNnews)
近段时间,大语言模型掀起了一股狂潮。 OpenAI 发布的 GPT-4 模型在包括编程在内的各个功能上都取得了令人瞩目的进步。微软研究院发布了一篇论文,展示了 GPT-4 能够在没有太多提示的情况下生成非常复杂的代码,如 3D 视频游戏。与此同时,OpenAI 还发布了 ChatGPT 插件。

大语言模型将如何影响软件的构建?
大语言模型能够提高专业开发人员的工作效率,GitHub Copilot 已经证明了这个方向的可行性。这意味着开发人员不必担心未来的工作前景,且软件的生产与分发方式不会发生剧烈的变化。
然而,大语言模型的影响力不仅于此。大语言模型将成为专业程序员的工具,但过于关注狭隘的用途可能会导致我们错失未来推动更大变化的潜力。
因为我认为在短时间内有可能所有的计算机用户都将有能力开发小型软件工具,并描述他们希望如何修改正在使用的软件。换句话说,大语言模型将发展成为支持用户编程的工具,普通人无需掌握编程的复杂性即可充分利用计算机。就目前的情况而言,这一愿景在将模糊的非正式意图转化为正式的可执行代码方面遇到了瓶颈。而接下来,在大规模语言模型的助力下,瓶颈正在迅速打开。
如果这种假设成真,我们将看到人们使用软件的方式出现一些惊人的变化:
-
一次性脚本:普通计算机用户可以借助 AI,每天创建并执行几十次脚本,以执行数据分析、视频编辑等任务,或自动执行一些繁琐的任务。
-
一次性 GUI:人们将使用 AI 创建整个 GUI 应用程序,这种应用程序只能执行特定的某个任务,仅包含他们需要的功能,不会膨胀。
-
构建取代购买:企业内部将开发更多软件,以满足他们特定的需求,而不是购买现成的 SaaS,因为根据具体情况定制软件更便宜。
-
修改/扩展:消费者和企业需要扩展和修改现有软件的能力,在 AI 的助力下,开发新功能或调整匹配用户的工作流程将更容易。
-
重组:吸取各个应用程序的精华,并创建一个集百家之长的混合应用程序。
所有这些变化不仅仅是加快当前软件的生产过程。软件的创建时机、由谁创建以及出于什么目的,都将发生变化。

大规模语言模型+可延展软件
接下来,将深入探讨大语言模型可能为软件创建和分发带来的广泛变化,而且还会影响到人们与软件交互的方式。讨论的问题包括:
-
交互模型:哪种交互模型适合哪些任务?人们什么时候需要聊天机器人、一次性脚本或自定义的一次性 GUI?
-
软件定制:大规模语言模型如何实现可由用户拆分、重组和扩展的可延展软件?
-
意图规范:最终用户将如何与大规模语言模型交互,表达自己的意图?
-
模糊翻译器:大规模语言模型如何实现以前不可能实现的共享数据基础?
-
用户授权:我们应该如何看待大规模语言模型时代的授权和代理与授权和自动化?

聊天机器人应该何时使用?
在大规模语言模型时代用户交互模型将如何进化?特别是,聊天机器人可能会接管哪些类型的任务?当我们考虑用不同的方式来武装最终用户时,这个问题的答案会特别重要。
我认为,虽然 ChatGPT 比 Siri 更强大,但聊天 UI 无法很好地完成许多任务,我们仍然需要图形用户界面。之后会讨论利用大规模语言模型帮助我们构建 UI 的混合交互模型。
最终,我们将达成一种有趣的设计:开放式计算媒体,用户可以直接学习和建立模型,大规模语言模型将作为媒体内的合作伙伴。
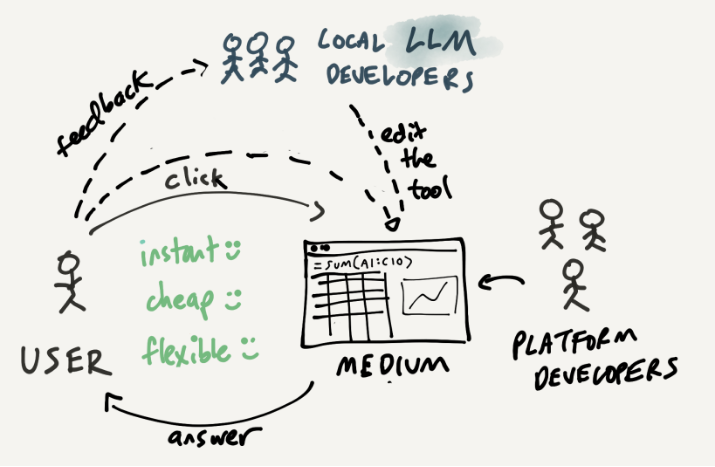
在深入展开讨论之前,首先声明:本文探讨的很多观点都源自个人的猜测,具有很大的不确定性。我甚至无法预测这些变化什么时候会出现。重点是,想象如何根据当前 AI 的发展状况,推断用户与计算机的新型交互,以及我们如何利用这项新技术来最大限度地加强最终用户的能力。

打破编程瓶颈
为什么大规模语言模型关系到普通用户使用计算机的能力?
几十年来,计算先驱们一直在努力实现最终用户编程的愿景:普通人也可以充分利用计算机,而不仅仅是使用程序员给他们的预制应用程序。Alan Kay 曾在1984 年写道:“我们希望像以前编辑文档一样编辑我们的工具。”
这个理念有很多表现形式。现代终端用户也或多或少地接触过编程系统,包括电子表格、Airtable、Glide 或 iOS 快捷方式,以及早期的 HyperCard、Smalltalk 和 Yahoo Pipes。
尽管其中一些产品取得了成功,但现在它们也面临一个基本难题的限制:帮助人们将粗略的想法转化为正式的可执行代码,这一步非常难。系统设计者尝试过超高级语言、友好的可视化编辑器和更好的语法、复杂性分层以及根据示例自动生成简单的代码。但事实证明,使用这些技术很难突破一定的复杂性上限。
我自己在工作中就遇到过编程瓶颈。几年前,我开发了一个名为 Wildcard 的最终用户编程系统,用户可以通过电子表格界面自定义网站。例如,在下面这个简短的演示中,你可以看到用户按照不同的顺序对 Hacker News 上的文章进行排序,然后将阅读时间添加到页面的文章中,这一切都是通过网页与电子表格的同步化实现的。
这个演示看上去很不错,对吧?
然而仔细观察,就会发现这个系统有两个略显尴尬的编程瓶颈。首先,用户必须能够编写小型电子表格公式来表达计算。虽然难度远小于学习一门成熟的编程语言,但对于新手用户来说依然是一个障碍。其次,在背后,Wildcard 需要特定于站点的抓取代码,才能将电子表格连接到网站。理论上,这些代码可以由开发人员编写和维护,并在最终用户社区中共享,但这需要付出巨大的努力。
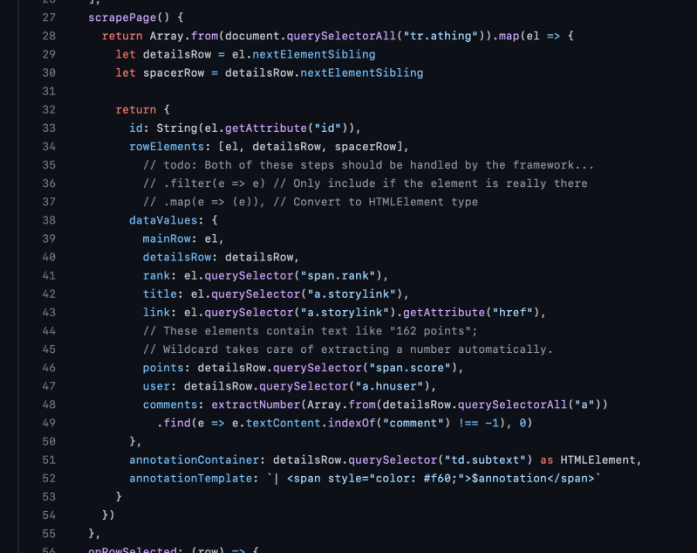
如今有了大规模语言模型,这些编程瓶颈就不再是限制因素了。将自然语言规范转化为网络抓取代码或者是电子表格公式正是目前大规模语言模型可以实现的代码生成过程。我们可以想象,让大规模语言模型帮忙抓取代码和生成公式,这样就无需任何人手动编写代码即可实现上述演示。在我做 Wildcard 的时候,这种的程序生成还只是一个幻想,而如今正在迅速变成现实。
不过,这个例子也提出了一个更深层次的问题。如果让大规模语言模型为我们修改网站,那又何必使用 Wildcard UI 呢?难道我们不能让 ChatGPT 重新排序网站并添加阅读时间吗?
我认为这个问题的答案尚不明朗。将电子表格视为网站基础数据的另一种视图具有很大的价值,我们可以直接查看和操作这些数据。点击列的标题即可让表格中的数据按顺序排列感觉很好,而且比输入“按列 X 排序”更快。允许用户直接查看和编辑电子表格公式,可以让他们拥有更多的控制权。
所以,用户界面仍然很重要。我们可以想象,大规模语言模型的具体、有针对性的角色应该是帮助用户定制和构建软件,而不是将几十年的交互设计抛诸脑后。

GPT 真的可以编写代码吗?
现如今,GPT-4 的编程能力究竟如何?这很难一句话概括。了解当前 GPT-4 能力的最好方法是看一些正面和负面的例子,然后自行体会,最好是亲自尝试一下。
寻找正面的例子并不难。就个人而言,我已经成功地使用 GPT-4 编写了一次性的 Python 代码来处理数据,而且我妻子也使用 ChatGPT 编写了一些 Python 代码来抓取网站的数据。微软研究院最近发布的一篇论文发现 GPT-4(使用了零样本提示技术) 可以生成在浏览器中运行的复杂 3D 游戏,如下所示。

但负面的例子也不难发现。根据我的经验,GPT-4 在解决相对简单的算法问题时仍然会感到困惑。前几天,我试着用它来制作一款 React 应用程序来执行一些简单的视频编辑任务,虽然 90% 的工作都完成了,但未能正确地进行一些拖动/调整大小的交互。所以说,GPT-4 并非完美。GPT-4 给人的感觉就像一个初级开发者,打字速度很快,知道很多库,但是很粗心,而且经常犯迷糊。
就我个人而言,比较看好大规模语言模型的发展,下面说几个不太明显的理由。
首先,迭代是大规模语言模型的必要组成部分。当第一次生成的代码无法运行时,你只需粘贴收到的错误消息,或描述意外行为,GPT 就会进行调整。例如,网上有一位设计师(不会编写游戏代码)通过多次迭代创建了一款视频游戏。
参考链接:https://twitter.com/ammaar/status/1637592014446551040
GPT-4 开发者的直播中也有一些使用错误消息进行迭代的示例。仔细想想,人类编写代码的方式也大抵如此,第一次尝试也不一定总能成功。
有些程序员对人工智能持怀疑态度,我经常看到这样的一个笑话:“太好了,现在大家都不需要编写代码了,只需要编写准确无误的计算机行为规范……”(意思是说,那不就是代码吗?!)我认为这种观点的目光太短浅。大规模语言模型可以与用户反复沟通,并提出问题,帮助他们编写规范,而且还可以通过常识填补不明确的细节。这并不意味着,实现起来很简单,但我希望看到这些方面取得进步。我已经成功地要求 GPT-4 提问,从而澄清我指定的规格。
还有一个重点,根据 MSR 论文以及我自己的有限实验,GPT-4 的编程水平较之 GPT-3 似乎已有了很大进步,而且上升幅度很大。照着这个节奏发展下去,那么下一代模型也将呈现巨大的提升。
编程的难度因上下文而异,我们可能会看到专业软件工程与最终用户编程之间的差异。一方面,我们可能会看到最终用户编程的难度远小于专业编程,因为许多任务可以通过简单的编程来完成,主要工作就是多个库粘合在一起,不需要新颖的算法创新。
另一方面,与熟练的程序员相比,在新手终端用户主导的流程中,如果 AI 给出错误的代码,那么造成的后果更严重。面对大规模语言模型给出的愚蠢建议,熟练的程序员大可以一笑了之,然后自己编写代码,或者利用自己掌握的技术与大规模语言模型一起调试。但最终用户就会束手无策,甚至在刚开始的时候发现不了这些问题。虽然这些都是真实的问题,但我认为并非无法克服。一直以来,最终用户编写的电子表格程序不仅杂乱无章,而且漏洞百出,但我们依然有办法应付过去,即使这对于注重正确性的专业软件开发人员来说是无法忍受的。

聊天本质上是一种有限的互动
下面,来讨论文本的正题:在这个新的计算时代,交互模型将如何发展?首先,我们来看一看聊天这种交互模式。计算的未来真的是计算机使用自然语言与我们对话?
我认为关键是要注意到聊天机器人令我们失望的两个主要原因。首先,聊天机器人的能力有限(比如 Siri ),而且无法完成你希望它做的事情。但从根本上来看,姑且不论机器人的质量如何,聊天本质上就是一种有限的交互模式。
例如,最近 OpenAI 的 Greg Brockman 在 ChatGPT 插件发布期间发布了下面这条推文,他与 ChatGPT 通过自然语言交互,要求它剪辑出视频的前 5 秒:
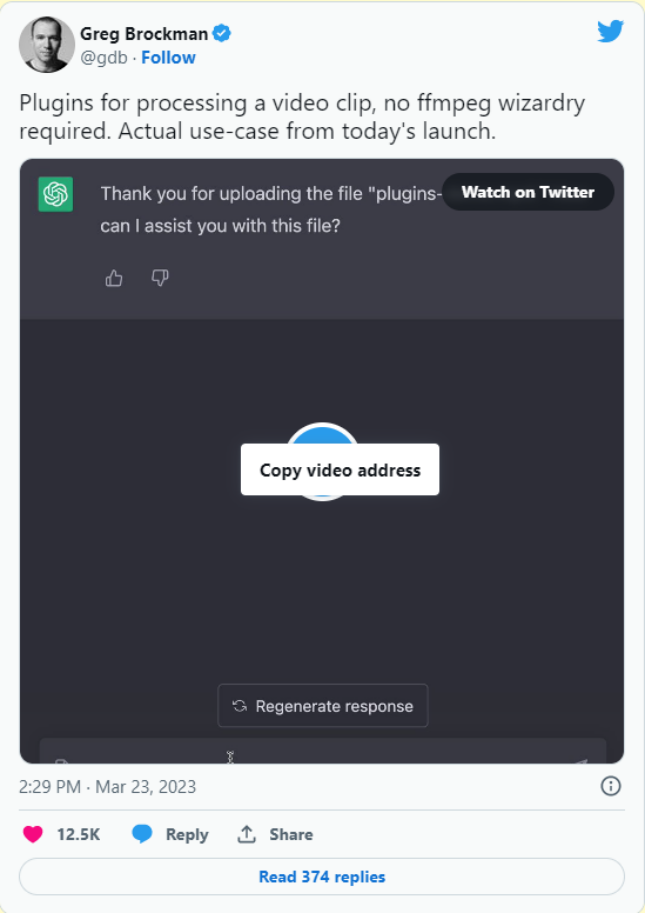
一方面,对于了解计算机工作原理的来说,这个演示确实很了不起,而且我对 ChatGPT 的发展可能性充满了期待。
然而,从另一种意义上说,这个演示很愚蠢,因为我们有现成的软件,这些软件提供的界面可以直接剪辑视频,而且具有丰富的交互反馈。例如,iPhone 就提供了剪辑视频的用户界面,不仅有丰富的反馈,而且能精准控制剪辑。我们放着这样的软件不用,却不厌其烦地跟 ChatGPT 来回沟通:“请剪辑出前 4.8 秒”?

现在,我明白了 Greg Brockman 的演示重点不仅仅是剪辑视频,而是展示了广泛的可能性。但这里仍有一些重要事项需要注意:聊天界面不仅非常慢而且不准确,而且还需要有意识地了解用户的思维过程。
当我们使用一把好工具(比如一把锤子、一支画笔、一副滑雪板或一个汽车方向盘)时,潜意识里我们会与这些工具融为一体。我们可以进入心流状态,应用肌肉记忆,实现精细控制,甚至可能发挥创造力或创造艺术成果。无论机器人多么好,聊天的感觉永远不如开车。Terry Winograd 和 Fernando Flores 于 1986 年出版的著作《Understanding Computers and Cognition》中详细阐述了这一点:
在驾驶汽车时,控制交互通常是透明的。你不会思考:“方向盘需要转动多少才能绕过前面的弯道?”事实上,你甚至不会意识到自己在使用方向盘(除非有什么东西侵入)……汽车的设计经过了长期的发展,才成就了如今人车合一的状态。这不是通过让汽车像人一样交流来实现的,而是相关领域(道路上的行驶)提供驾驶员与驾驶动作之间的正确耦合来实现的。

顾问与应用
从更高的层面来思考聊天与直接操作的问题。一种方法是反思人类顾问团队通过 Slack 互动的感觉,与直接使用某个应用来完成工作。然后,我们就能看到大规模语言模型在其中发挥的作用。
假设你想获取一些业务相关的指标,比如下个季度的销售预测。你会怎么做?
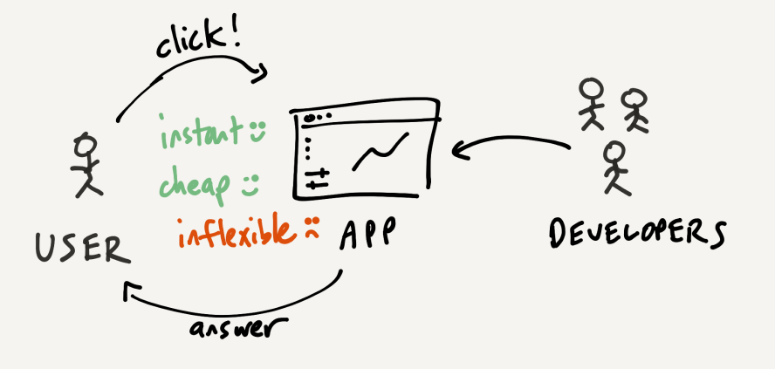
一种方法是询问熟练的业务分析团队。你可以将问题发给他们,但因为他们很忙,所以可能需要几个小时才能得到回复,而且这个过程的成本很高,因为你占用了他们的时间。如果是一些简单的任务,可能得不偿失,但最大的好处是灵活,顾问团队拥有丰富的经验和知识,他们可以执行许多不同的任务。
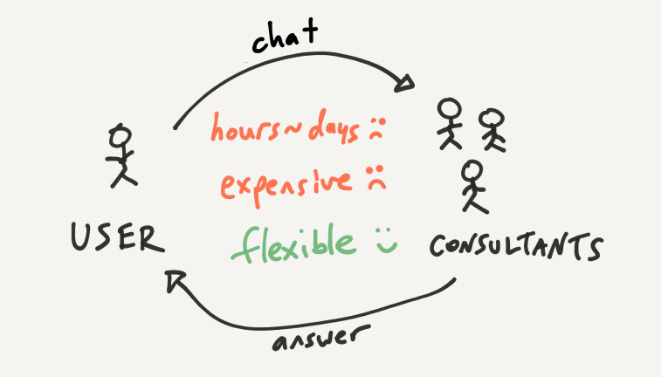
相比之下,另一种选择是使用自助分析平台,你可以点击其中的某些仪表板。这种方式更快、更便宜,而且还无需打扰分析师。仪表板提供了强大的交互操作,比如排序、过滤和缩放。
那么缺点是什么?使用应用的灵活性不如与顾问合作。当你需要执行平台不支持的任务时,就不得不寻求帮助或切换到其他工具。你可以尝试向分析平台的开发人员发送电子邮件,但通常都不会有任何结果。你与开发人员之间没有建立有意义的反馈循环,你只能希望软件更灵活。
到此为止,我们建立了比较基准,下面我们来想象一下如何利用大规模语言模型。
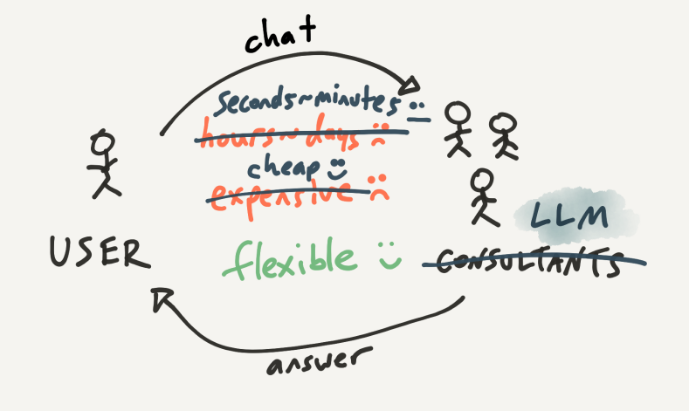
假设我们可以利用 ChatGPT 代替人工分析师团队来完成任务,同时还可以保持同等程度的灵活性。(虽然如今的模型还达不到这个水平,但会越来越接近。)情况会发生怎样的变化?首先,大规模语言模型的成本远低于人工;其次,它的响应速度更快,因为它不忙,也不会喝咖啡休息。这些都是主要优势。但是,与它对话需要等待几秒钟(甚至是几分钟),比 GUI 或方向盘的操作要慢得多。
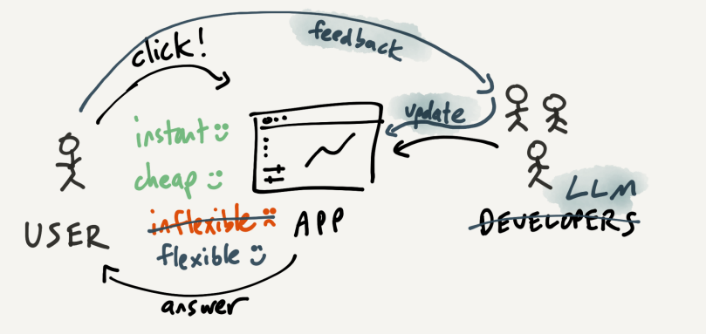
下面,我们来思考将大规模语言模型应用到应用程序模型。我们从一个交互式分析应用程序开始,但这次假设我们有一个大规模语言模型担当的开发团队供我们使用,情况会怎样?首先,我们可以询问大规模语言模型如何使用应用程序,这比阅读文档更容易。
但更大的优势在于,大规模语言模型提供的帮助远不止于此,而且还可以更新应用程序。当我们提供有关添加新功能的反馈时,我们的请求不会在看不到头的等待队列中丢失。他们会立即做出回应,与我们沟通如何实现该功能。当然,有些新功能不需要提供给每个人,可以只服务于我们。这在经济上是可行的,因为我们不依赖人类开发团队来更新应用程序。
请注意,这些只是目前的粗略设想。我们没有提及如何实现这个模型的细节。当前软件构建方式的许多细节导致这类的即时定制非常具有挑战性。
不过,重要的是我们已经在交互中建立了两个循环。对于内部循环,我们可以使用快速直接的操作界面与工具融为一体。对于外部循环,当我们达到现有应用程序的极限时,就可以有意识地向大规模语言模型提供反馈并构建新功能。这样不仅可以保持住 UI 的优势,同时还可以增加灵活性。

从应用程序到计算媒体
这个双重交互循环让你想起了什么?
想想电子表格是如何工作的。假设你在电子表格中建立了一个财务模型,然后可以尝试修改单元格中的数字来应对具体场景,这就相当于直接操作的内部循环。
但是,你也可以编辑公式。电子表格不仅仅是专注于特定任务的“应用程序”,它更接近于一种通用的计算媒介,可以让你灵活地表达多种任务。“平台开发人员”(电子表格的创建者)为你提供了一组可用于制作许多工具的通用原语。
我们可以通过下图描述与电子表格交互的双循环。你可以编辑电子表格中的数字,同时也可以编辑公式,即编辑工具:
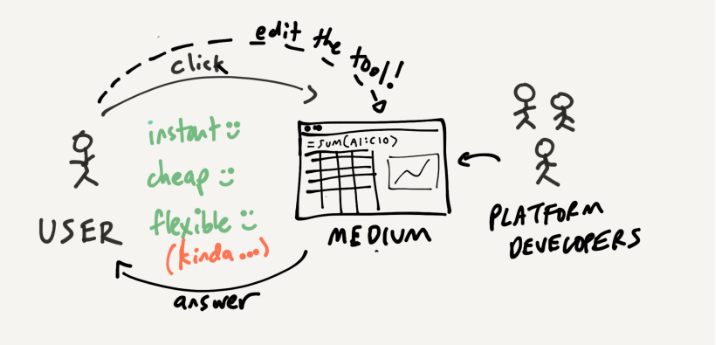
通过上图,我们可以看出电子表格有一定程度的灵活性。但是,个人用户使用电子表格时,很容易达到知识的极限。在现实生活中,电子表格比上图更加灵活。原因是图中缺少使用电子表格的关键组成部分:协作。

与本地开发人员合作
大多数团队都有领域专家和技术专家,你可以和他们一起协作来制作电子表格。而且重要的是,你与一起制作电子表格的人之间的关系完全不同于常见的“开发人员”与“最终用户”。Bonnie Nardi和James Miller 于 1990 年发表的关于协作开发电子表格的论文中解释说,假设 Betty 是一位非常熟悉财务的 CFO,而 Buzz 是电子表格编程专家:
Betty 和 Buzz 之间的关系看似就是最终用户与开发人员,我们很容易想象二人合作开发电子表格的常见情况:Betty 根据她对领域的了解说明定电子表格应该做什么,而 Buzz 则负责实现。
然而,实际情况并非如此。他们合作开发电子表格时,有两个重要方面完全不同于上述常见情况:
(1)Betty 在没有 Buzz 帮助的情况下构建了基本的电子表格。她通过编程将参数、数据值和公式融入到了模型中。此外,用户界面的设计和实现也由 Betty 全权负责。她使用颜色、阴影、字体、轮廓和空白单元格来组织和显示电子表格中的信息。
(2)当 Buzz 帮助 Bettry 处理电子表格中最复杂的部分(例如绘图或复杂公式)时,他需要在 Betty 的工作成果之上来表达。他在 Betty 的基本电子表格中添加了一些更高级的代码,Betty 是主要开发人员,而 Buzz 担任的是顾问的角色。
这是系统设计和实现责任的一个重要转变。非程序员可以负责电子表格的大部分开发,实现大型应用程序,如果他们必须使用传统的编程技术,则无法承担这些工作。非程序员可能永远学不会递归函数和嵌套循环,但他们可以非常高效地使用电子表格。由于缺乏经验的用户参与了电子表格的开发,当他们发现即将触及自己的知识极限,或者他们对更复杂的编程技术感兴趣时,就更加有动力与经验丰富的开发人员交流。
因此,我们应该在描述使用电子表格的流程图中添加 Buzz 这样的“本地开发人员”,由他们在迭代的外层再加一层,用户在建模自己的工具时可以获得他们的帮助。因为他们与用户在同一个团队,所以相较于第三方应用程序或平台的开发人员,向他们寻求帮助要容易得多。最重要的是,随着时间的推移,用户会逐步掌握更多使用电子表格的功能,因为他们参与了开发过程。
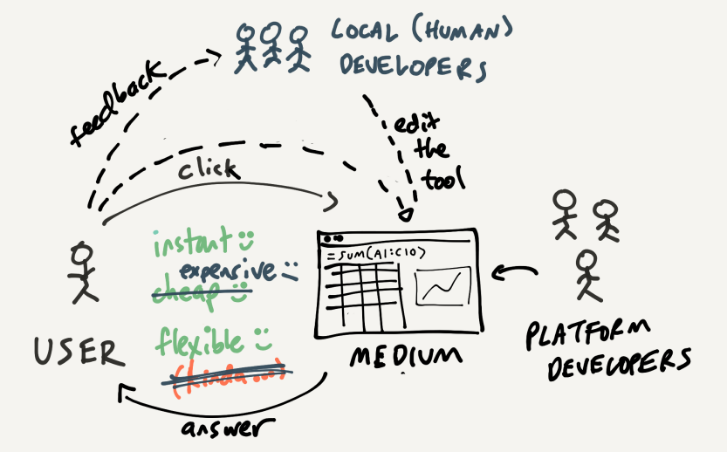
总的来说,有了本地开发人员,电子表格的使用将更加灵活,虽然这种方法也有一定的成本,因为需要人类技术专家参与其中。如果你们团队没有电子表格专家,怎么办?你还是需要通过网络搜索复杂的电子表格编程……
在这种情况下,我们就可以考虑让大规模语言模型扮演本地开发人员的角色。也就是说,主要由用户主导电子表格的创建,但在需要时就某些公式寻求技术帮助。大规模语言模型不仅可以创建完整的解决方案,还可以教用户下次如何自己创建解决方案。
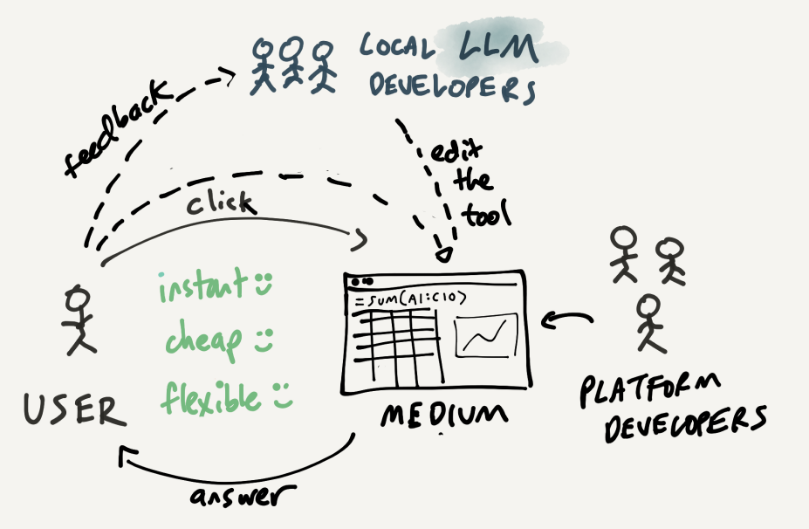
在我看来,上图展示的流程非常吸引人。有一个内部交互循环,用户可以充分利用直接操作的全部功能;有一个外部循环,用户可以在开放式媒体中更深入地编辑他们的工具。他们可以在 AI 的支持下编辑工具,并提高处理媒体的能力。随着时间的推移,他们可以学习公式的基础知识以及 VLOOKUP 的工作原理等。这种结构性知识有助于用户思考如何利用工具,也有助于他们审核大规模语言模型的输出。
在 ChatGPT 的世界中,用户完全依赖人工智能,对其内部机制一无所知。在以 AI 为助手的计算媒体中,用户对AI的依赖将随着时间的推移逐渐减少,因为他们会逐渐适应媒体。
截止到目前为止,开放式计算媒体的设计一直受编程瓶颈问题的制约。而大语言模型提供了一种前景可观的方法,可以更灵活地将自然语言转化为代码,这就提出了一个问题:什么样的强大计算媒体适合这种新情况?

☞百度发打假声明:目前文心一言无官方 App;吴恩达LeCun直播回怼马斯克:汽车都没发明要什么安全带|极客头条
☞ChatGPT 一统所有 AI 模型入口,四步实现文本分类、图像生成等 24 种复杂任务!
☞阿里版 ChatGPT 突然官宣!我们用 16 个提问,火速进行了测评……

20年前,《新程序员》创刊时,我们的心愿是全面关注程序员成长,中国将拥有新一代世界级的程序员。20年后的今天,我们有了新的使命:助力中国IT技术人成长,成就一亿技术人!
更多推荐



 9
9 0
0- 0



 已为社区贡献12380条内容
已为社区贡献12380条内容

所有评论(0)