
GPU池化如何帮助AI业务混合部署
随着软件定义算力的普及,我们还将不断深入探索,加大技术与业务的融合力度,让GPU池化技术惠及更多AI企业!
前情提要
在之前的文章《对比,还原真实的GPU池化》中,我们通过对比,论述了GPU池化的多业务安全隔离、资源动态释放、多平台支持的优势。这些优势有助于解决GPU共享问题,从根源上提高GPU利用率,降低TCO,提高业务效率。
然而,GPU池化不仅仅只是GPU共享,在共享的基础之上,GPU池化还提供很多实用的功能,帮助人工智能业务更好的落地,实现对GPU资源的高效管理。今天,我们从业务的角度来看一下GPU池化的高级功能。
业务类型与业务现状
AI业务按类型大致可以分成以下几种:
1. 在线推理类业务,这类业务时效性要求较高,比如身份证识别、人脸识别、智能外呼等;
2. 离线推理业务,这类业务时效性要求没那么高,比如文档智能抽取、资料审核、量化分析等;
3. 模型训练任务,主要用于上述各种算法模型的更迭,运行时间较长,运行时段灵活。
通常,为了确保业务的隔离性、相互之间无干扰、保障服务的SLA,大多数企业都是将各个业务分别部署在独立的GPU卡上,如下图:
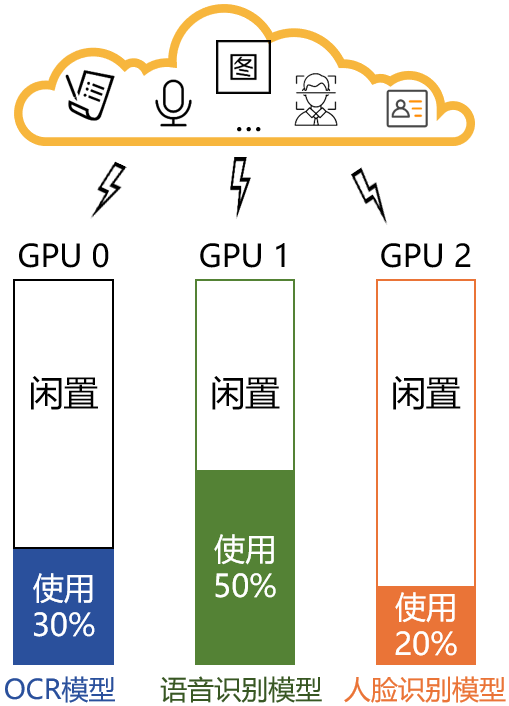
这个部署方式SLA是有保障了,但是也带来了一些问题:
1. 闲置资源较多。
2. 业务数量与GPU数量深度绑定,随着大规模AI应用的上线,GPU数量容易成为业务扩展的瓶颈。
3. 扩容GPU服务器成本高昂,交付周期长。
4. 在线、离线、训练业务交叉轮流使用,变动流程繁琐,协调成本高,交付速度慢,体验不佳。
5. 缺少全局统一的GPU资源配置和监控中心。
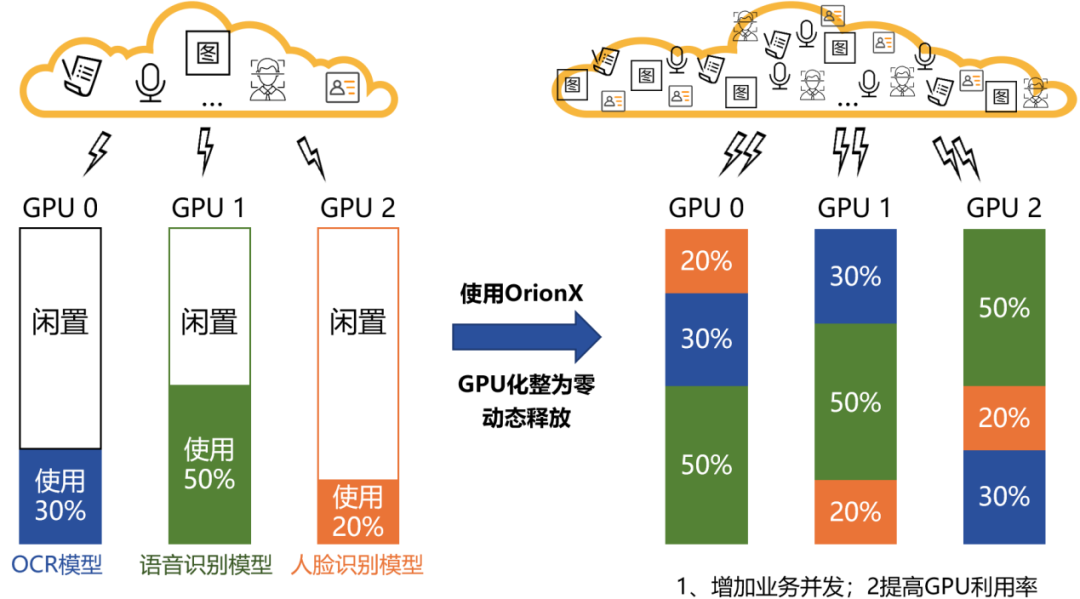
GPU池化优化的场景一:多个在线推理混合部署
通常在大多数推理场景下,GPU卡很难发挥100%的性能,如果简单的按卡为单位进行分配,会有很多资源闲置浪费。
为此,我们可以将GPU卡的算力和显存根据实际业务需求进行切分,分成若干个虚拟GPU,每个虚拟GPU给到一个业务使用。这样,多个在线推理业务可以部署在同一张GPU上。
业务收益:①充分挖掘和有效利用了现有GPU资源,可以服务和支撑更多业务,满足了业务对弹性并发的需求。②提高GPU利用率,消除硬件瓶颈。
OrionX池化能力关键词:化整为零,动态释放。
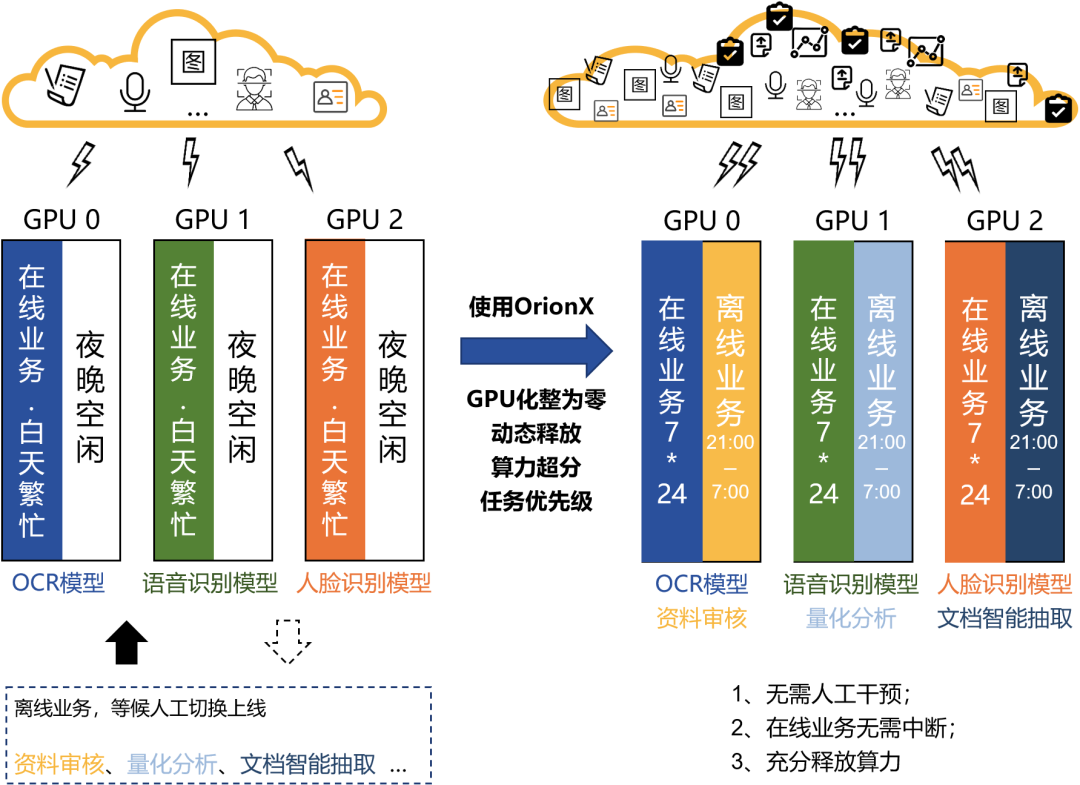
GPU池化优化的场景二:在/离线推理混合部署,算力超分,昼夜复用
某些在线推理业务,在时间维度有着非常显著的时间分布特性,比如OCR模型、身份识别等。它们在白天上班时间有着频率极高的业务请求量,在晚上下班之后请求量变得极低。与之相对应的是对GPU算力的占用也呈现出强烈的波峰波谷效应——在业务请求密集的时间段,GPU算力几乎100%运转;到了夜晚几乎无任何业务请求,算力100%闲置。
为了复用这部分算力资源开展离线业务,运维人员需要在夜晚手动调整在线业务部署,再拉起离线推理业务。在线/离线业务变更涉及资源分配、网络调整等一系列动作,变动流程繁琐,需要一定的资源、人力协调成本。同时,算力资源运维监控缺乏统一界面呈现,运维人员无法第一时间获取资源利用情况。
为了削峰填谷,错峰运行,我们可以有更简化,更智能的办法。OrionX支持任务级别的自动化管理,可以设定任务的自动上线时间及运行周期。在夜间在线业务低谷期,离线业务定时上线,开始执行离线审核类业务,业务完成后,离线业务自动下线。
与此同时,在线业务无需下线,可以不间断运行。OrionX支持算力超分,允许单个GPU卡分配超过100%的算力资源。因此,我们可以将在线与离线两个业务同时调度到一个GPU卡上同时运行。由于在线与离线业务存在客户响应时间的差异,因此我们支持对这两个业务设置不同优先级。夜晚,当在线业务有请求到来时,OrionX优先保障高优先级的在线业务所需的算力资源,离线业务应用此时暂时挂起,等待在线业务处理完成后再继续执行。
业务收益:①无需人工干预。②在线业务无需中断。③充分释放算力,提升GPU整体使用效率。
OrionX池化能力关键词:化整为零,动态释放,算力超分,任务优先级。
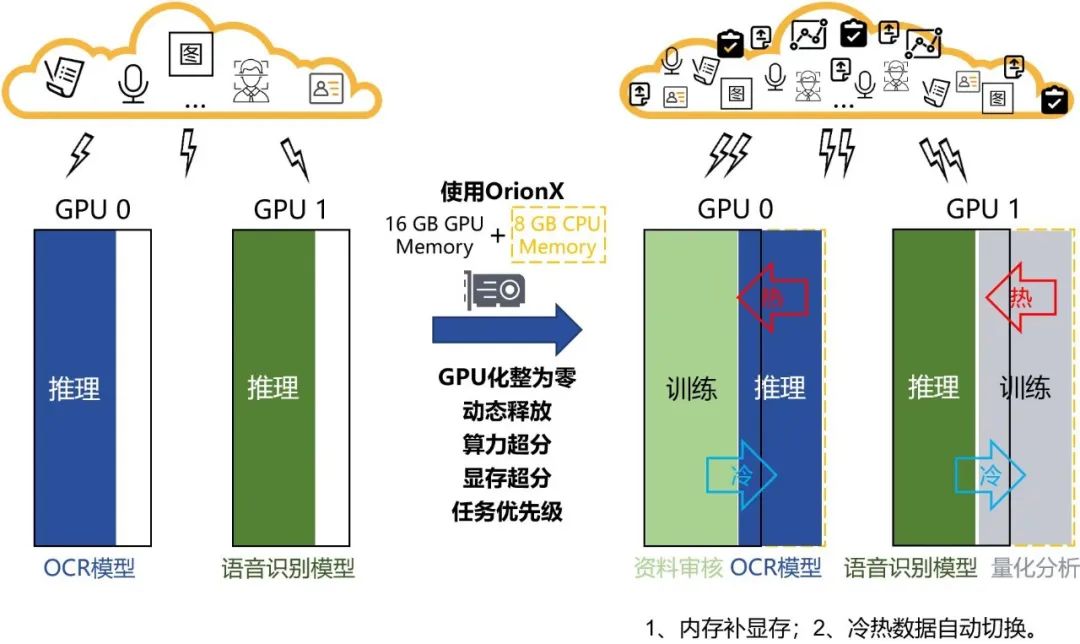
GPU池化优化的场景三:训练/推理混合部署,显存扩展,分时复用
在削峰填谷这个路径上,我们还可以向前进一步探索更大的扩展空间,比如加载训练任务进行复用。推理业务主要在上班时间运行,而训练任务的运行时段则比较灵活,通过合理搭配训练和推理业务,就可以利用二者呈现出的运行时段的互补性,极大的提高GPU资源的利用率。
然而,训练任务需要的显存通常比推理要大得多,如果要把两者同时加载在一起复用,很大概率会超过显存上限。那么这个时候就要使用显存超分。
显存超分是一个用系统内存补充显存的技术,补充进来的内存将被用作显存的“缓存”,冷/热数据可以自动的在显存与“缓存”之间进行切换。该技术可以突破物理GPU卡显存的上限,再叠加上算力超分,可以赋予虚拟GPU更从容的分配能力。同时再结合OrionX的任务调度与任务优先级,即可实现GPU资源合理分配。
白天,推理业务优先占用GPU,保证在上班高负载下的服务质量。到了晚上或节假日,推理业务请求量很少,系统自动将显存数据切换至内存上,把GPU资源调度给训练业务。晚间或次日白天有推理业务请求时系统自动将推理业务的数据从内存中加载到显存中,GPU算力资源又调度回推理业务。
如果在非工作时间,推理业务有请求达到,系统会自动调度以保证高优先级的推理业务的及时响应,系统会即刻将缓存在内存中的推理数据切换至显存,保障推理业务的优先权。
整个切换过程可以全程自动化、周期化、不改变系统部署、不影响业务的正常运行,从而实现训练+推理叠加的模式。
业务收益:①突破显存限制,提升扩展能力。②增加业务吞吐量。③无需人工干预。
OrionX池化能力关键词:化整为零,动态释放,算力超分,显存超分,任务优先级。
结语
技术的道路从来都不是一蹴而就的,需要持续不断的努力与探索。软件定义GPU的道路也是一样。GPU虚拟化解决了GPU共享的问题,降低了硬件成本。在虚拟化技术之上延伸而出的GPU池化技术,能够扩展出更多实用的功能,这些技术可以帮助企业解决业务规模化与自动化问题,进一步提高其开发及工作效率。
随着软件定义算力的普及,我们还将不断深入探索,加大技术与业务的融合力度,让GPU池化技术惠及更多AI企业!
关于OrionX AI算力资源池化软件:
趋动科技的OrionX AI算力资源池化解决方案帮助客户构建数据中心级AI算力资源池,使用户应用无需修改就能透明地共享和使用数据中心内任何服务器之上的AI加速器。OrionX不但能够帮助用户提高AI算力资源利用率,而且可以极大便利用户AI应用的部署。OrionX通过软件定义AI算力,颠覆了原有的AI应用直接调用物理GPU的架构,增加软件层,将AI应用与物理GPU解耦合。AI应用调用逻辑的OrionX vGPU,再由OrionX将OrionX vGPU需求匹配到具体的物理GPU。OrionX架构实现了GPU资源池化,让用户高效、智能、灵活地使用GPU资源,达到了降本增效的目的。
OrionX通过构建GPU资源池,让企业内的AI用户共享数据中心内所有服务器上的GPU算力。AI开发人员不必再关心底层资源状况,专注于更有价值的业务层面,让应用开发变得更加便捷。根据客户测算,OrionX猎户座软件可以每年提升50%AI算法工程师人效、提升AI资源利用率3-8倍以及让客户总体拥有成本下降80%。

20年前,《新程序员》创刊时,我们的心愿是全面关注程序员成长,中国将拥有新一代世界级的程序员。20年后的今天,我们有了新的使命:助力中国IT技术人成长,成就一亿技术人!
更多推荐



 0
0 0
0- 0



 已为社区贡献12387条内容
已为社区贡献12387条内容

所有评论(0)