推荐系统经典模型 Wide & Deep 论文剖析
作者 | 梁唐来源 | TechFlow(id:TechFlow)今天我们剖析的也是推荐领域的经典论文,叫做Wide & Deep Learning for Recommend...


作者 | 梁唐
来源 | TechFlow(id:TechFlow)
今天我们剖析的也是推荐领域的经典论文,叫做Wide & Deep Learning for Recommender Systems。它发表于2016年,作者是Google App Store的推荐团队。这年刚好是深度学习兴起的时间。这篇文章讨论的就是如何利用深度学习模型来进行推荐系统的CTR预测,可以说是在推荐系统领域一次深度学习的成功尝试。
著名的推荐模型Wide & deep就是出自这篇论文,这个模型因为实现简单,效果不俗而在各大公司广泛应用。因此它同样也可以认为是推荐领域的必读文章之一。
长文预警,建议先马后看。

摘要
在大规模特征的场景当中,我们通常(2016年之前)是使用将非线性特征应用在线性模型上的做法来实现的,使用这种方式,我们的输入会是一个非常稀疏的向量。虽然我们要实现这样的非线性特征,通过一些特征转化以及特征交叉的方法是可以实现的,但是这会需要消耗大量的人力物力。
这个问题其实我们之前在介绍FM模型的时候也曾经提到过,对于FM模型来说,其实解决的也是同样的问题。只是解决的方法不同,FM模型的方法是引入一个n x k的参数矩阵V来计算所有特征两两交叉的权重,来降低参数的数量以及提升预测和训练的效率。而在本篇paper当中,讨论的是使用神经网络来解决这个问题。
解决问题的核心在于embedding,embedding直译过来是嵌入,但是这样并不容易理解。一般来说我们可以理解成某些特征的向量表示。比如Word2Vec当中,我们做的就是把一个单词用一个向量来表示。这些向量就称为word embedding。embedding有一个特点就是长度是固定的,但是值一般是通过神经网络来学习得到的。
我们可以利用同样训练embedding的方式来在神经网络当中训练一些特征的embedding,这样我们需要的特征工程的工作量就大大地减少。但是仅仅使用embedding也是不行的,在一些场景当中可能会引起过拟合,所以我们需要把线性特征以及稀疏特征结合起来,这样就可以让模型既不会陷入过拟合,又可以有足够的能力可以学到更好的效果。

简介
正如我们之前文章所分享的一样,推荐系统也可以看成是搜索的排序系统。它的输入是一个用户信息以及用户浏览的上下文信息,返回的结果是一个排好序的序列。
正因为如此,对于推荐系统来说,也会面临一个和搜索排序系统一个类似的挑战——记忆性和泛化性的权衡。记忆性可以简单地理解成对商品或者是特征之间成对出现的一种学习,由于用户的历史行为特征是非常强的特征,记忆性因此可以带来更好的效果。但是与之同时也会有问题产生,最典型的问题就是模型的泛化能力不够。
对于泛化能力来说,它的主要来源是特征之间的相关性以及传递性。有可能特征A和B直接和label相关,也可能特征A与特征B相关,特征B与label相关,这种就称为传递性。利用特征之间的传递性, 我们就可以探索一些历史数据当中很少出现的特征组合,从而获得很强的泛化能力。
在大规模的在线推荐以及排序系统当中,比如像是LR这样的线性模型被广泛应用,因为这些模型非常简单、拓展性好、性能很强,并且可解释性也很好。这些模型经常用one-hot这样的二进制数据来训练,举个例子,比如如果用户安装了netflix,那么user_installed_app=netflix这个特征就是1,否则就是0。因此呢,一些二阶特征的可解释性就很强。
比如用户如果还浏览过了Pandora,那么user_installed_app=netflix,impression_app=pandora这个联合特征就是1,联合特征的权重其实就是这两者的相关性。但是这样的特征需要大量的人工操作,并且由于样本的稀疏性,对于一些没有在训练数据当中出现过的组合,模型就无法学习到它们的权重了。
但是这个问题可以被基于embedding的模型解决,比如之前介绍过的FM模型,或者是深度神经网络。它可以通过训练出低维度下的embedding,用embedding向量去计算得到交叉特征的权重。然而如果特征非常稀疏的话,我们也很难保证生成的embedding的效果。比如用户的偏好比较明显,或者是商品比较小众,在这样的情况下会使得大部分的query-item的pair对没有行为,然而由embedding算出来的权重可能大于0,因此而导致过拟合,使得推荐结果不准。对于这种特殊的情况,线性模型的拟合、泛化能力反而更好。
在这篇paper当中,我们将会介绍Wide & Deep模型,它在一个模型当中兼容了记忆性以及泛化性。它可以同时训练线性模型以及神经网络两个部分,从而达到更好的效果。
论文的主要内容有以下几点:
-
Wide & Deep模型,包含前馈神经网络embedding部分以及以及线性模型特征转换,在广义推荐系统当中的应用
-
Wide & Deep模型在Google Play场景下的实现与评估,Google Play是一个拥有超过10亿日活和100w App的移动App商店

推荐系统概述
这是一张经典的推荐系统的架构图:
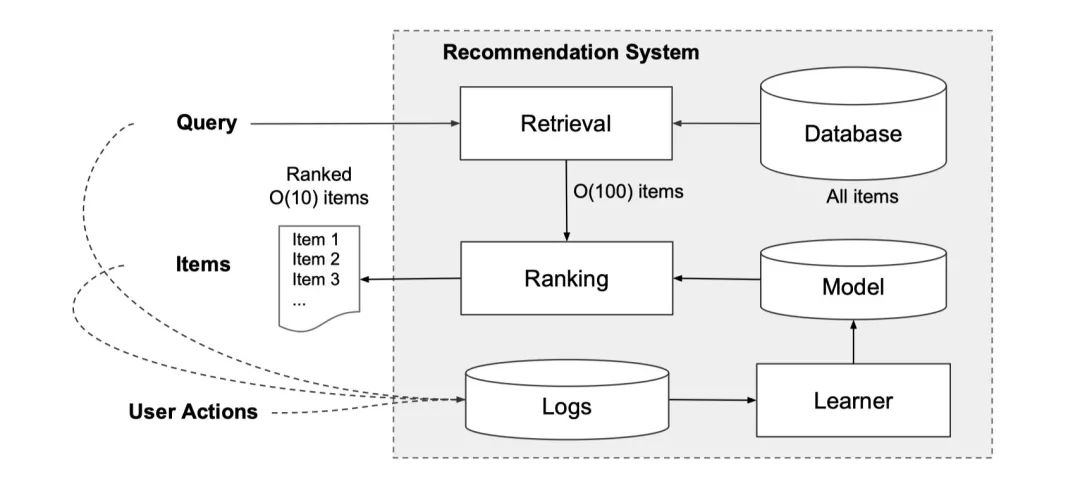
当用户访问app store的时候会生成一个请求,这个请求当中会包含用户以及上下文的特征。推荐系统会返回一系列的app,这些app都是模型筛选出来用户可能会点击或者是购买的app。当用户看到这些信息之后,会产生一些行为,比如浏览(没有行为)、点击、购买,产生行为之后,这些数据会被记录在Logs当中,成为训练数据。
我们看下上面部分,也就是从DataBase到Retrieval的部分。由于Database当中的数据量过大,足足有上百万。所以我们想要在规定时间内(10毫秒)给所有的app都调用模型打一个分,然后进行排序是不可能的。所以我们需要对请求进行Retrieval,也就是召回。Retrieval系统会对用户的请求进行召回,召回的方法有很多,可以利用机器学习模型,也可以进行规则。一般来说都是先基于规则快速筛选,再进行机器学习模型过滤。
进行筛选和检索结束之后,最后再调用Wide & Deep模型进行CTR预估,根据预测出来的CTR对这些APP进行排序。在这篇paper当中我们同样忽略其他技术细节,只关注与Wide & Deep模型的实现。

Wide & Deep原理
首先我们来看下业内的常用的模型的结构图:
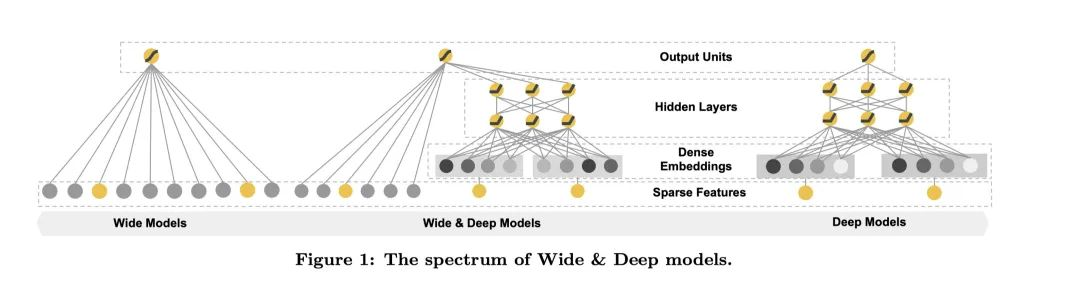
这张图源于论文,从左到右分别展示了Wide模型,Wide & Deep模型以及Deep模型。从图上我们也看得出来所谓的Wide模型呢其实就是线性模型,Deep模型是深度神经网络模型。下面结合这张图对这两个部分做一个详细一点的介绍。
Wide部分
Wide部分其实就是一个泛化的形如 的线性模型,就如上图左边部分所展示的一样。y是我们要预测的结果,x是特征,它是一个d维的向量 。这里的d是特征的数量。同样w也是一个d维的权重向量 ,b呢则是偏移量。这些我们在之前线性回归的模型当中曾经都介绍过,大家应该也都不陌生。
特征包含两个部分,一种是原始数据直接拿过来的数据,另外一种是我们经过特征转化之后得到的特征。最重要的一种特征转化方式就是交叉组合,交叉组合可以定义成如下形式:
这里的 是一个bool型的变量,表示的是第i个特征的第k种转化函数 的结果。由于使用的是乘积的形式,只有所有项都为真,最终的结果才是1,否则是0。比如"AND(gender=female,language=en)"这就是一个交叉特征,只有当用户的性别为女,并且使用的语言为英文同时成立,这个特征的结果才会是1。通过这种方式我们可以捕捉到特征之间的交互,以及为线性模型加入非线性的特征。
Deep部分
Deep部分是一个前馈神经网络,也就是上图当中的右侧部分。
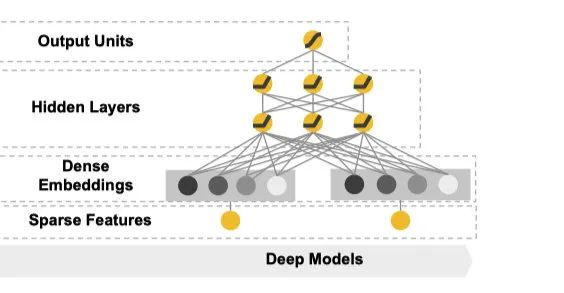
我们观察一下这张图会发现很多细节,比如它的输入是一个sparse的feature,可以简单理解成multihot的数组。这个输入会在神经网络的第一层转化成一个低维度的embedding,然后神经网络训练的是这个embedding。这个模块主要是被设计用来处理一些类别特征,比如说item的类目,用户的性别等等。
和传统意义上的one-hot方法相比,embedding的方式用一个向量来表示一个离散型的变量,它的表达能力更强,并且这个向量的值是让模型自己学习的,因此泛化能力也大大提升。这也是深度神经网络当中常见的做法。
Wide & Deep合并
Wide部分和Deep部分都有了之后,通过加权的方式合并在一起。这也就是上图当中的中间部分。
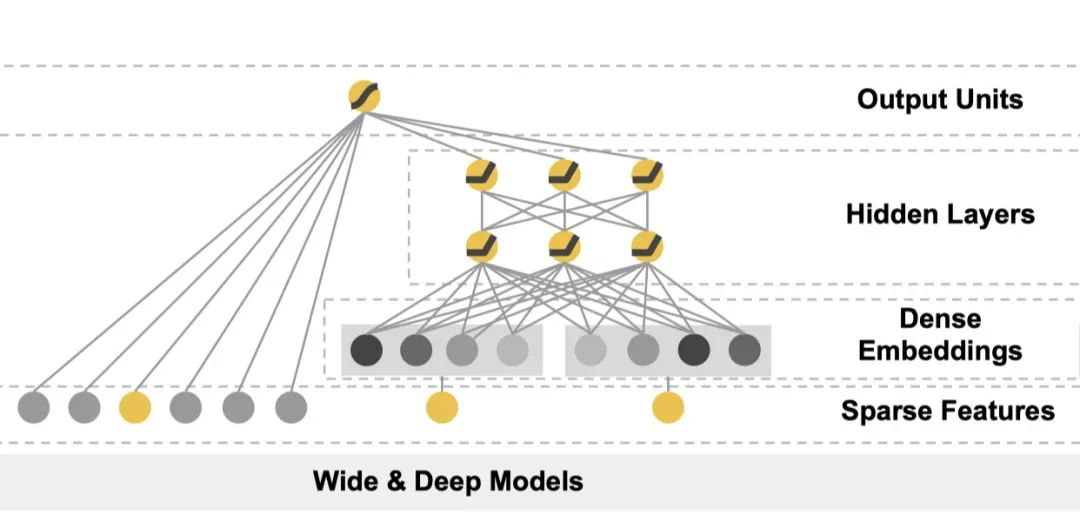
最上层输出之前其实是一个sigmoid层或者是一个linear层,就是一个简单的线性累加。英文叫做joint,paper当中还列举了joint和ensemble的区别,对于ensemble模型来说,它的每一个部分是独立训练的。而joint模型当中的不同部分是联合训练的。ensemble模型当中的每一个部分的参数是互不影响的,但是对于joint模型而言,它当中的参数是同时训练的。
这样带来的结果是,由于训练对于每个部分是分开的,所以每一个子模型的参数空间都很大,这样才能获得比较好的效果。而joint训练的方式则没有这个问题,我们把线性部分和深度学习的部分分开,可以互补它们之间的缺陷,从而达到更好的效果,并且也不用人为地扩大训练参数的数量。

系统实现
app推荐的数据流包含了三个部分:数据生产、模型训练以及模型服务。用一张图来展示大概是这样的:
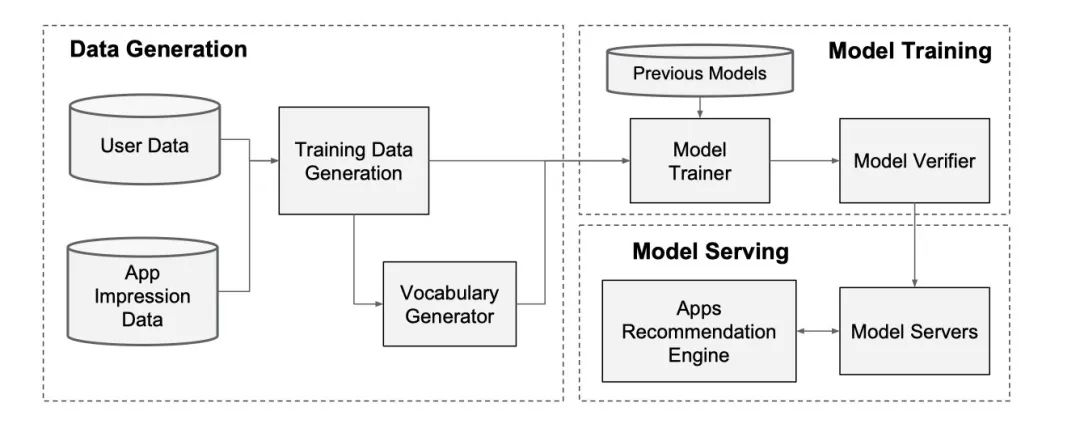
数据生产
在数据生产的阶段,我们使用app在用户面前曝光一段时间作为一个样本,如果这个app被用户点击安装,那么这个样本被标记为1,否则标记为0。这也是绝大多数推荐场景下的做法。
在这个阶段,系统会去查表,把一些字符串类别的特征转化成int型的id。比如娱乐类的对应1,摄影类的对应2,比如收费的对应0,免费的对应1等等。同时会把数字类型的特征做标准化处理,缩放到[0, 1]的范围内。
模型训练
paper当中提供了一张模型的结构图:
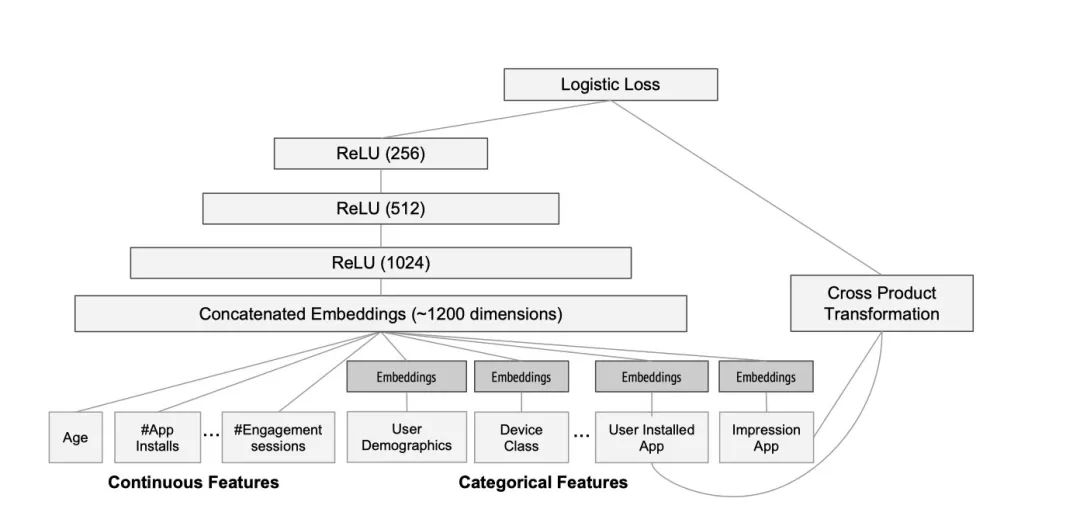
从上图当中我们可以看到,左边是一些连续性的特征,比如年龄,安装的app数量等等,右边是一些离散型的特征,比如设备信息,安装过的app等等。这些离散型的特征都会被转化成embedding,之后和右边的连续性特征一起进入神经网络进行学习。paper当中使用的是32维的embedding。
模型每次训练会使用超过500 billion的样本数量进行训练,每次搜集到了新的训练数据都会训练模型。但是如果每一次训练我们都从头开始的话,显然会非常缓慢,并且会浪费大量的计算资源。因此paper当中选择了一种增量更新的模式,也就是说在模型更新的时候,会加载旧模型的参数,再使用最新的数据进行更新训练。在新模型更新上线之前,会先验证模型的效果,确认效果没有问题之后再进行更新。
模型服务
当模型被训练好被加载进来之后,对于每一个请求,服务器都会从recall系统当中获取一系列候选的app,以及用户的特征。接着调用模型对每一个app进行打分,获取了分数之后,服务器会对候选的app按照分数从高到低进行排序。
为了保证服务器的响应能力,能够在10ms时间内返回结果,paper采取了多线程并发执行的方法。老实讲,我觉得这份数据有点虚。因为现在的模型没有不使用并发执行的,但即使是并发执行,使用深度学习进行预测也很难保证效率能够到达这种程度。也许是还采用了其他的一些优化,但是paper里没有全写出来。

模型结果
为了验证Wide & Deep模型的效果,paper在真实的场景当中从两个角度进行了大量的测试。包括app的获取量以及服务的表现。
App 获取量
在线上环境进行了为期3周的A/B测试,1个桶作为对照桶,使用之前版本的线性模型。1个桶使用Wide & Deep模型,另外一个桶只使用Deep模型,去除了linear的部分。这三个桶各自占据了1%的流量,最后得到的结果如下:
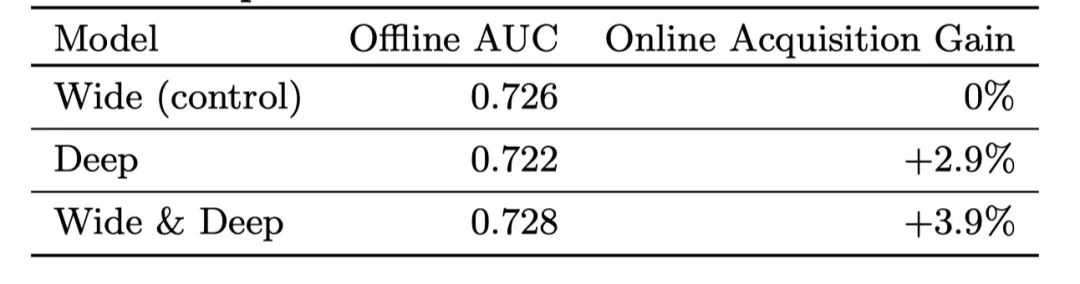
Wide & Deep模型不仅AUC更高,并且线上APP的获取量也提升了3.9%。
服务性能
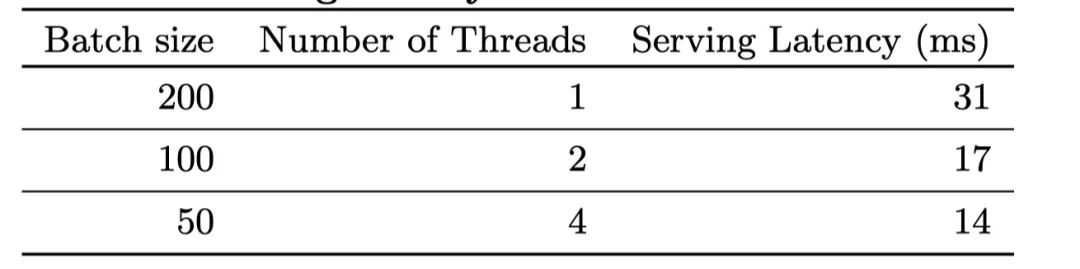
对于推荐系统来说,服务端的性能一直是一个很大的问题,因为既需要承载大量的流量,也需要保证延迟非常短。而使用机器学习或者是深度学习模型来进行CTR的预测,本身的复杂度是非常高的。根据paper当中的说法,高峰时期,他们的服务器会承载1千万的qps。
如果使用单线程来处理一个batch的数据需要31毫秒,为了提升速度,他们开发了多线程打分的机制,并且将一个batch拆分成了几个部分进行并发计算。通过这样的方式,将客户端的延迟降低到了14毫秒。

代码实现
光说不练假把式,Wide & Deep在推荐领域一度表现不俗,并且模型的实现也不复杂。我曾经使用Pytorch实现过一个简易版本,贴出来抛砖引玉给大家做一个参考。
import torch
from torch import nn
class WideAndDeep(nn.Module):
def __init__(self, dense_dim=13, site_category_dim=24, app_category_dim=32):
super(WideAndDeep, self).__init__()
# 线性部分
self.logistic = nn.Linear(19, 1, bias=True)
# embedding部分
self.site_emb = nn.Embedding(site_category_dim, 6)
self.app_emb = nn.Embedding(app_category_dim, 6)
# 融合部分
self.fusion_layer = nn.Linear(12, 6)
def forward(self, x):
site = self.site_emb(x[:, -2].long())
app = self.app_emb(x[:, -1].long())
emb = self.fusion_layer(torch.cat((site, app), dim=1))
return torch.sigmoid(self.logistic(torch.cat((emb, x[:, :-2]), dim=1)))
由于我当时的应用场景比较简单,所以网络结构只有三层,但是原理是一样的,如果要应用在复杂的场景当中,只需要增加特征以及网络层次即可。


更多精彩推荐
☞上线两天用户 10W+,这款 AI 知识图谱小程序有多牛?
☞专访华为杨海松:立足合作伙伴价值,构建健康HarmonyOS生态
☞实名羡慕!蚂蚁员工激励达 1376.9 亿,人均能在杭州买套 283 平的房子?
☞或许,人工智能比你还要老
☞当飞猪遇上 Serverless | 云原生 Talk
☞Harvest遭受闪电贷攻击,黑客通过Curve盗走2300万美元
点分享点点赞点在看

20年前,《新程序员》创刊时,我们的心愿是全面关注程序员成长,中国将拥有新一代世界级的程序员。20年后的今天,我们有了新的使命:助力中国IT技术人成长,成就一亿技术人!
更多推荐



 2
2 0
0- 0



 已为社区贡献12373条内容
已为社区贡献12373条内容

所有评论(0)