长肥管道(LFT)中TCP的艰难处境与打法
作者 | dog250责编 | 张文出处 | https://blog.csdn.net/dog250/article/details/113020804一年多没有深夜惊起而作文了...

作者 | dog250 责编 | 张文
出处 | https://blog.csdn.net/dog250/article/details/113020804
一年多没有深夜惊起而作文了,又逢雨夜,总结一些思路。
带宽一定的情况下,网络的吞吐理论上不受时延的影响,虽然管道长了一点,但截面积是一定的。
然而当你用 TCP 去验证这一结论时,往往得不到你想要的结果:
一个长肥管道很难被单条 TCP 连接填满(一条 TCP 流很难在长肥管道中达到额定带宽)!
我们做以下拓扑:
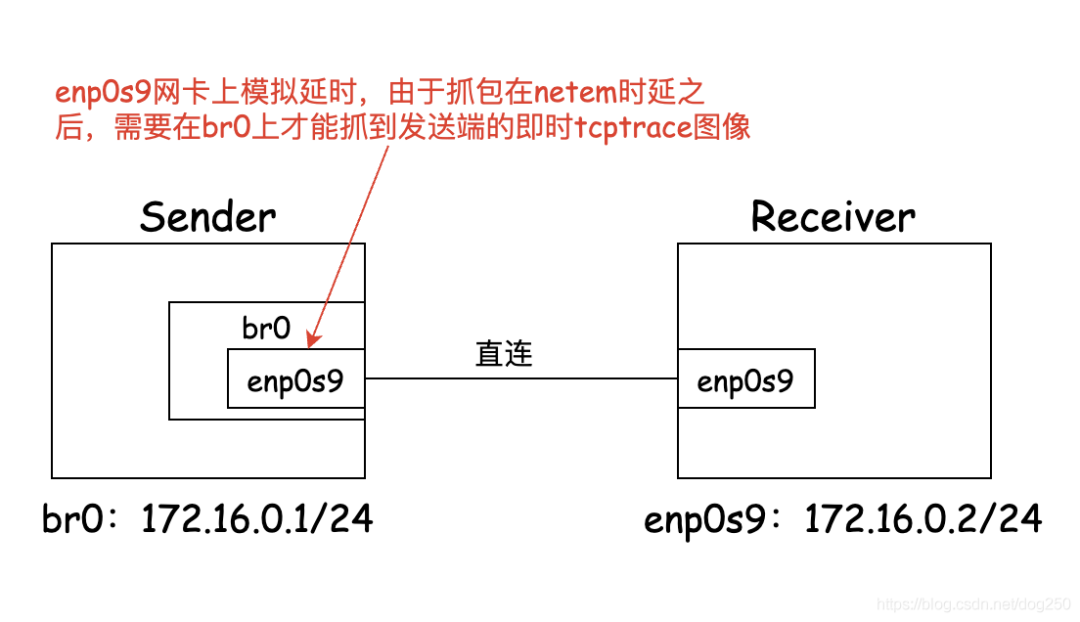
首先我测算裸带宽作为基准。
测试接收端为 172.16.0.2,执行 iperf -s,测试发送端执行:
iperf -c 172.16.0.2 -i 1 -P 1 -t 2
结果如下:
------------------------------------------------------------Client connecting to 172.16.0.2, TCP port 5001TCP window size: 3.54 MByte (default)------------------------------------------------------------[ 3] local 172.16.0.1 port 41364 connected with 172.16.0.2 port 5001[ ID] Interval Transfer Bandwidth[ 3] 0.0- 1.0 sec 129 MBytes 1.09 Gbits/sec[ 3] 1.0- 2.0 sec 119 MBytes 996 Mbits/sec[ 3] 0.0- 2.0 sec 248 MBytes 1.04 Gbits/sec...
很显然,当前直连带宽为 1 Gbits/Sec。
为了模拟一个 RTT 为 100ms 的长肥管道,我在测试发送端用 netem 模拟一个 100ms 的延时(仅仅模拟延时,无丢包):
tc qdisc add dev enp0s9 root netem delay 100ms limit 10000000
当然,也可以在测试发送端和测试接收端各用 netem 模拟一个 50ms 的延时以分担 hrtimer 的开销。
再次执行 iperf,结果惨不忍睹:
------------------------------------------------------------Client connecting to 172.16.0.2, TCP port 5001TCP window size: 853 KByte (default)------------------------------------------------------------[ 3] local 172.16.0.1 port 41368 connected with 172.16.0.2 port 5001[ ID] Interval Transfer Bandwidth[ 3] 0.0- 1.0 sec 2.25 MBytes 18.9 Mbits/sec[ 3] 1.0- 2.0 sec 2.00 MBytes 16.8 Mbits/sec[ 3] 2.0- 3.0 sec 2.00 MBytes 16.8 Mbits/sec[ 3] 3.0- 4.0 sec 2.00 MBytes 16.8 Mbits/sec[ 3] 4.0- 5.0 sec 2.88 MBytes 24.1 Mbits/sec[ 3] 0.0- 5.1 sec 11.1 MBytes 18.3 Mbits/sec
和理论推论完全不符!长肥管道的传输带宽看起来并非不受时延的限制…
那么问题来了,到底是什么在阻止一个 TCP 连接填满一个长肥管道呢?
为了让事情变得简单和可分析,我使用最简单的 Reno 算法进行测试:
net.ipv4.tcp_congestion_control = reno
并且我关掉了两台机器的 TSO/GSO/GRO 等 Offload 特性。在此前提下,故事开始了。
需要明确的一个常识就是,一个长肥管道的容量等于带宽和时延的乘积,即 BDP。
那么,单条 TCP 流填满一个长肥管道看起来只需要满足三个条件即可:
-
为了让发送端可以发送 BDP 这么多的数据,接收端需要通告一个 BDP 大小的窗口。
-
为了让发送端有 BDP 这么多的数据可发,发送端需要有 BDP 这么大的发送缓冲区。
-
为了让 BDP 这么多的数据背靠背顺利通过长肥管道,网络不能拥塞(即需要单流独享带宽)。
OK,如何满足以上三个条件呢?
我先来计算 100ms 的 1 Gbits/Sec 管道的 BDP 有多大,这很容易计算,以字节为单位,它的值是:
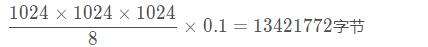
大概 13MB 的样子。
以 MTU 1500 字节为例,我将 BDP 换算成数据包的数量,它的值是:
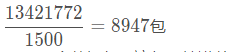
即 8947 个数据包,这便是填满整个长肥管道所需的拥塞窗口的大小。
为了满足第一个要求,我将接收端的接收缓冲区设置为 BDP 的大小(可以大一些但不能小):
net.core.rmem_max = 13420500net.ipv4.tcp_rmem = 4096 873800 13420500
同时在启动 iperf 的时候,指定该 BDP 值作为窗口,为了让接收窗口彻底不成为限制,我将窗口指定为 15M 而非刚刚好的 13M(Linux 将内核协议栈的 skb 本身的开销也会计算在内):
iperf -s -w 15m
提示符显示设置成功:
------------------------------------------------------------Server listening on TCP port 5001TCP window size: 25.6 MByte (WARNING: requested 14.3 MByte)------------------------------------------------------------
OK,接下来看发送端,我将发送端的发送缓冲同样设置成 BDP 的大小:
net.core.wmem_max = 13420500net.ipv4.tcp_wmem = 4096 873800 13420500
现在我来测试一把,结论依然不尽如人意:
...[ 3] 38.0-39.0 sec 18.5 MBytes 155 Mbits/sec[ 3] 39.0-40.0 sec 18.0 MBytes 151 Mbits/sec[ 3] 40.0-41.0 sec 18.9 MBytes 158 Mbits/sec[ 3] 41.0-42.0 sec 18.9 MBytes 158 Mbits/sec[ 3] 42.0-43.0 sec 18.0 MBytes 151 Mbits/sec[ 3] 43.0-44.0 sec 19.1 MBytes 160 Mbits/sec[ 3] 44.0-45.0 sec 18.8 MBytes 158 Mbits/sec[ 3] 45.0-46.0 sec 19.5 MBytes 163 Mbits/sec[ 3] 46.0-47.0 sec 19.6 MBytes 165 Mbits/sec...
现在的限制已经不是缓冲区了,现在的限制是 TCP 的拥塞窗口!拥塞窗口似乎很矜持,并没有完全打开。
我对 TCP Reno 拥塞控制算法太熟悉了,以至于我可以肯定这个如此之低的带宽利用率正是它 AIMD 行为的结果。那么很好办,我绕开它便是了。
这是一个无丢包的场景,于是我可以亲自手工指定一个拥塞窗口,这只需要一个 stap 脚本即可完成:
#!/usr/bin/stap -g
%{#include <linux/skbuff.h>#include <net/tcp.h>%}
function alter_cwnd(skk:long, skbb:long)%{ struct sock *sk = (struct sock *)STAP_ARG_skk; struct sk_buff *skb = (struct sk_buff *)STAP_ARG_skbb; struct tcp_sock *tp = tcp_sk(sk); struct iphdr *iph; struct tcphdr *th;
if (skb->protocol != htons(ETH_P_IP)) return;
th = (struct tcphdr *)skb->data; if (ntohs(th->source) == 5001) { // 手工将拥塞窗口设置为恒定的BDP包量。 tp->snd_cwnd = 8947; }%}
probe kernel.function("tcp_ack").return{ alter_cwnd($sk, $skb);}
以下是指定拥塞窗口为 BDP 后的测试结果:
...[ 3] 0.0- 1.0 sec 124 MBytes 1.04 Gbits/sec[ 3] 1.0- 2.0 sec 116 MBytes 970 Mbits/sec[ 3] 2.0- 3.0 sec 116 MBytes 977 Mbits/sec[ 3] 3.0- 4.0 sec 117 MBytes 979 Mbits/sec[ 3] 4.0- 5.0 sec 116 MBytes 976 Mbits/sec...
嗯,差不多是把 BDP 填满了。但事情并没有结束。
现在问题又来了,我知道,TCP Reno 是锯齿状上探,那么应该是探到 BDP 时才会丢包,进而执行乘性减窗的,其平均带宽至少也应该是 50%才对(对于 Reno,合理值应该在 75%上下),为什么测试数据显示带宽利用率只有10%左右呢?
Reno 在检测到丢包时才会执行乘性减窗的,既然拥塞窗口远没有达到带宽时延所允许的最大容量,为什么会丢包呢?是什么阻止 Reno 继续上探窗口呢?
无论是收发端的 ifconfig tx/rx 统计,还是 tc qdisc 的统计,均无丢包,并且我仔细核对了两端的抓包,确实有包没有到达接收端:
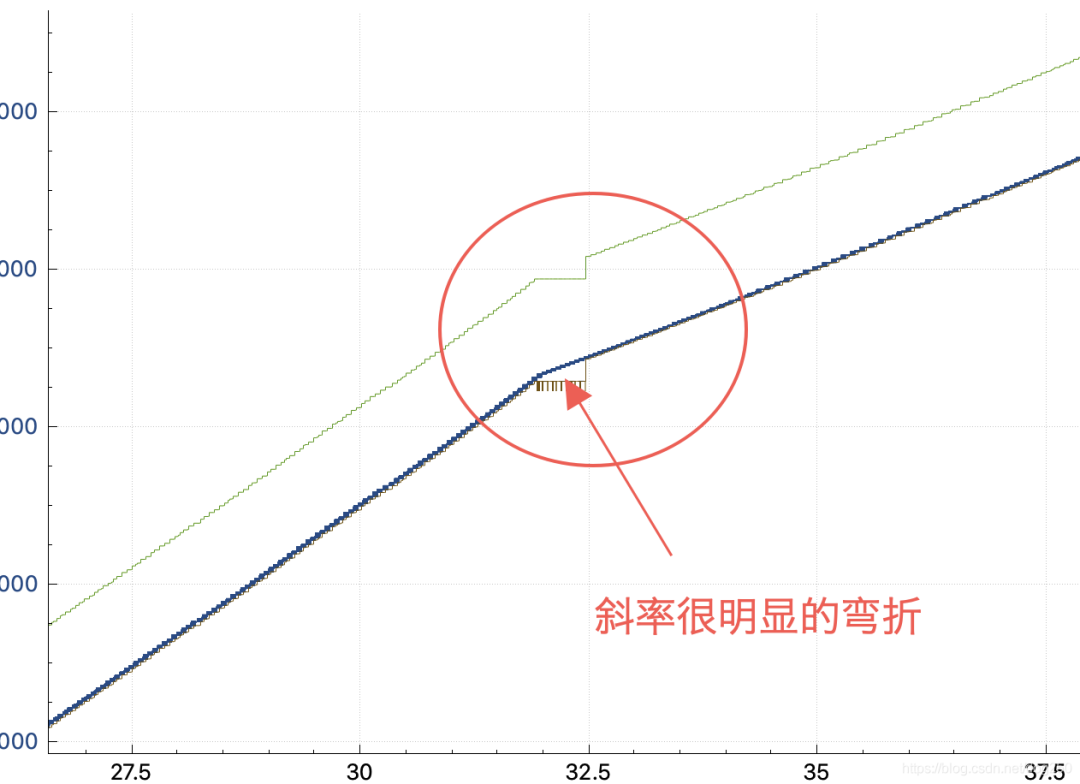
答案就是 噪声丢包! 也就是链路误码,比特反转,信号衰亡之类。
一般而言,当带宽利用率达到一定百分比时,几乎总会出现偶然的,概率性的噪声丢包,这非常容易理解,事故总会发生,概率高低而已。这个噪声丢包在独享带宽的链路上使用 ping -f 就可以测试:
# ping -f 172.16.0.2PING 172.16.0.2 (172.16.0.2) 56(84) bytes of data........^C--- 172.16.0.2 ping statistics ---1025 packets transmitted, 1018 received, 0.682927% packet loss, time 14333msrtt min/avg/max/mdev = 100.217/102.962/184.080/4.698 ms, pipe 10, ipg/ewma 13.996/104.149 ms
然而,哪怕只是一个偶然的丢包,对 TCP Reno 的打击也是巨大,好不容易缓慢涨上来的窗口将立即减为一半!这就是为什么在长肥管道中,TCP 连接的拥塞窗口很难爬上来的原因。
OK,在我的测试环境中,我敢肯定丢包是噪声引发的,因为测试 TCP 连接完全独享带宽,没有任何排队拥塞,因此我可以屏蔽掉乘性减窗这个动作,这并不难:
#!/usr/bin/stap -g
%{#include <linux/skbuff.h>#include <net/tcp.h>%}
function dump_info(skk:long, skbb:long)%{ struct sock *sk = (struct sock *)STAP_ARG_skk; struct sk_buff *skb = (struct sk_buff *)STAP_ARG_skbb; struct tcp_sock *tp = tcp_sk(sk); struct iphdr *iph; struct tcphdr *th;
if (skb->protocol != htons(ETH_P_IP)) return;
th = (struct tcphdr *)skb->data; if (ntohs(th->source) == 5001) { int inflt = tcp_packets_in_flight(tp); // 这里打印窗口和inflight值,以观测窗口什么时候能涨到BDP。 STAP_PRINTF("RTT:%llu curr cwnd:%d curr inflight:%d \n", tp->srtt_us/8, tp->snd_cwnd, inflt); }%}
probe kernel.function("tcp_reno_ssthresh").return{ // 这里恢复即将要减半的窗口 $return = $return*2}
probe kernel.function("tcp_ack"){ dump_info($sk, $skb);}
现在继续测试,先让上述脚本执行起来,然后跑 iperf。
这次我给 iperf 一个足够久的执行时间,等它慢慢将拥塞窗口涨到 BDP:
iperf -c 172.16.0.2 -i 1 -P 1 -t 1500
在 100ms RTT 的 1 Gbits/Sec 长肥管道中,拥塞窗口涨到 BDP 这么大将是一个漫长的过程,由于噪声丢包的存在,慢启动将很快结束,忽略起初占比很小的慢启动,按照每一个 RTT 窗口增加 1 个包估算,一秒钟大概增窗 10 个,一分钟就是 600 个,窗口爬升到 8000 多需要十几分钟。
…
去给蒸个鸡蛋顺便再开一罐刘致和臭豆腐,回来确认一下。
经过了大概 15 分钟,拥塞窗口不再增长,稳定在了 8980,这个值与我最初算出的 BDP 相当,下面的打印是我上面那个 stap 脚本的输出:
RTT:104118 curr cwnd:8980 curr inflight:8949RTT:105555 curr cwnd:8980 curr inflight:8828RTT:107122 curr cwnd:8980 curr inflight:8675RTT:108641 curr cwnd:8980 curr inflight:8528
而此时的带宽为:
...[ 3] 931.0-932.0 sec 121 MBytes 1.02 Gbits/sec[ 3] 932.0-933.0 sec 121 MBytes 1.02 Gbits/sec[ 3] 933.0-934.0 sec 121 MBytes 1.02 Gbits/sec...
窗口爬升到 BDP 所需的时间也符合预期。
看来,只要忽略了噪声丢包导致的丢包乘性减窗,Reno 事实上是可以探满 BDP 的!输出 1 Gbits/Sec 是如此的稳定,恰恰说明之前的丢包确实是噪声丢包,否则由于需要重传排队,带宽早就掉下去了。
那么,接下来的问题是,如果 TCP 已经探测到了最大的窗口值,它还会继续向上探测吗?也就是说,上面的输出中为什么最终拥塞窗口稳定在 8980 呢?
细节是,当 TCP 发现即便是增加窗口,也不会带来 inflight 的提升时,它就会认为已经到顶了,就不再增加拥塞窗口了。详见下面的代码段:
is_cwnd_limited |= (tcp_packets_in_flight(tp) >= tp->snd_cwnd);
由于数据包守恒,当 inflight 的值小于拥塞窗口时,说明窗口的配额尚未用尽,不必再增窗,而 inflight 的最终最大值是受限于 BDP 的物理限制的,因此它最终会是一个稳定值,从而拥塞窗口也趋于稳定。
OK,现在你已经知道如何用 TCP 单流灌满 BDP 了,这真的好难!
对于 Reno 而言,即便是我有能力忽略噪声丢包(事实上我们区分不出丢包是噪声引起的还是拥塞引起的),在长肥管道的大 RTT 环境中,每一个 RTT 时间才增窗1个数据包,这真是太慢了!长肥管道的“长”可以理解为增窗时间长,而“肥”则可以理解为距离目标最大窗口太远,这个理解非常尴尬地解释了 TCP 在长肥管道中是多么艰难!
在 Reno 之后,人们想到了很多优化手段,企图让 TCP 在长肥管道中的日子好过一点,但是无论是 BIC 还是 CUBIC,都是治标不治本,其思路和 Reno 几乎是一致的。
在最后窗口爬升的漫长等待中,事实上,噪声丢包仍然在持续进行,我只是当一只鸵鸟掩耳盗铃罢了,就当什么事都没有发生。然而,噪声丢包似乎并没有影响传输带宽的持续攀升,结果真的就像什么都没有发生。
当我手工指定了窗口为 BDP 或者当我屏蔽了窗口减半效应的前提下,由于开启了 SACK,偶然的噪声丢包被很快重传,带宽依然保持原速。 随着拥塞窗口的缓慢增加,发包量也在缓慢增加,随之而来的就是 iperf 测量传输速率的缓慢增加。大约等了 15 分钟,BDP 被填满,背靠背的数据流和背靠背的 ACK 流终于首尾相接,测量带宽达到了极限,这也完成了本文一开始的需求,即让一个 TCP 流填满一个长肥管道。
然而我很清楚,在现实环境中,首先,不允许我对协议栈采用 stap HOOK 的方式进行逻辑修改,比方说我不能去修改一条 TCP 连接的拥塞窗口,我只能无条件信任当前的拥塞控制算法,其次,即便我修改了拥塞窗口,比如我自己写了一个新的拥塞控制模块,其中将拥塞窗口写成了很大的值,或者我只是简单得屏蔽掉了乘性减窗,我会马上认识到,这种修改在现实中会让情况变得更糟!
我曾经就是如此不自量力。
一切似乎又回到了原点,这是一个老问题,我根本无法区分一次丢包是因为噪声还是因为拥塞,如果是后者,就必须乘性减窗。
BBR 绕开了这个难题。如前面实验数据显示,噪声丢包并不会影响实际的传输带宽和 RTT,但拥塞则会影响传输带宽和 RTT。BBR 正是通过直接测量传输带宽和 RTT 来计算发包速率的。我把拥塞算法切换成 BBR 后,再次 iperf 测试:
root@zhaoya:/home/zhaoya# iperf -c 172.16.0.2 -i 1 -P 1 -t 5------------------------------------------------------------Client connecting to 172.16.0.2, TCP port 5001TCP window size: 853 KByte (default)------------------------------------------------------------[ 3] local 172.16.0.1 port 41436 connected with 172.16.0.2 port 5001[ ID] Interval Transfer Bandwidth[ 3] 0.0- 1.0 sec 62.4 MBytes 523 Mbits/sec[ 3] 1.0- 2.0 sec 117 MBytes 980 Mbits/sec[ 3] 2.0- 3.0 sec 128 MBytes 1.08 Gbits/sec[ 3] 3.0- 4.0 sec 129 MBytes 1.08 Gbits/sec[ 3] 4.0- 5.0 sec 133 MBytes 1.12 Gbits/sec[ 3] 0.0- 5.0 sec 570 MBytes 955 Mbits/sec
5 秒的测试就能填满整个 BDP。
好吧,解决 TCP 在长肥管道中效率低下问题的方案似乎已经非常直接了,切换到 BBR 呗,但事情真的这么简单吗?
除了带宽利用率,拥塞控制还有一个重要指标,即公平性!
Reno/BIC/CUBIC 的 AIMD 背后是成熟的控制论模型,在数学上可以证明Reno(以及其后代 BIC,CUBIC)可以快速收敛到公平,然而 BBR 却不能!BBR 无法从数学上被证明是公平性友好的,这便是它和 Reno 家族拥塞控制算法的本质差距。
盗一个我之前文章里的图吧:
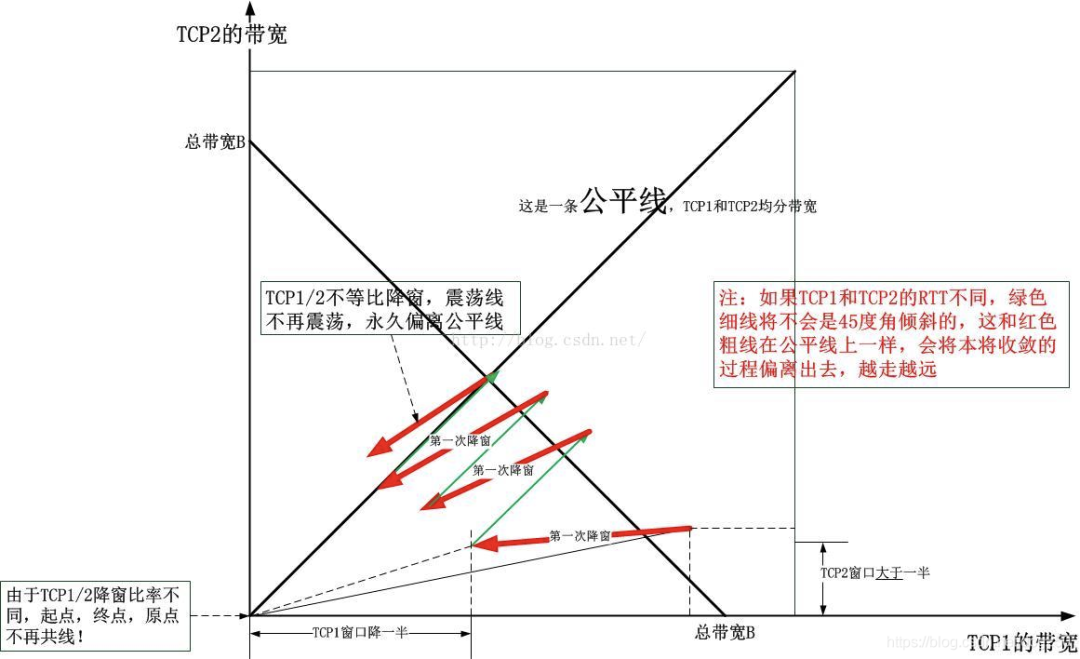
这个就是 Reno 家族 AIMD 为什么能收敛到公平的图解,BBR 画不出这样的图。
当我们面对问题的时候,需要看看历史,我们需要知道 Reno 是怎么来的。在1980 年代第一次出现大规模网络拥塞之前,TCP 是没有拥塞控制的,之后,Reno 的引入并非为了效率,而是为了在出现拥塞的时候快速收敛到公平。而CUBIC 在严格收敛的基础上用三次凸凹曲线来优化窗口探测的效率。
没有任何拥塞控制算法是为了提高单流吞吐而被引入的,相反,如果是为了保证公平性,它们的效果往往是降低了单流的吞吐。如果想提高单流的吞吐,回到1986 年之前就是了。
如果你是想通过超发来保持高效,那你和没有拥塞控制那个混乱的的年代大家所期求的一致。
到此为止,我一直没有脱离我自己搭建的理想测试环境,在独享带宽的直连环境下 TCP 的表现尚且如此,如果是公共网络,其中的随机噪声以及真正的拥塞更加难以预测,期待 TCP 单流吞吐爬升到一个比较高的水平更加不能指望。
那么,如果解决公共网络 TCP 在长肥管道中性能低下的问题呢?
见招拆招,把长管道切成短的呗!它基于以下的认知:
-
管道长,意味着窗口爬升慢,丢包感知慢,丢包恢复慢。
-
管道肥,意味着目标很远大,结合管道长的弱点,达到目标更加不易。
SDWAN 可以应对长肥管道中的这种尴尬!
有两种方法可以拆分长肥管道:
-
TCP 代理模式。可以通过多个透明代理接力将数据传输到遥远的目的地。
-
TCP 隧道模式。可以将大时延的 TCP 流封装在小时延的 TCP 隧道里接力传输。
无论哪种方式都是将路径进行了分割,既然处理不好长路径,那就分别处理短路径呗。具体可以看:
https://blog.csdn.net/dog250/article/details/83997773
为了保持端到端的透明性,我比较倾向于使用TCP隧道来切分长肥管道。
关于 TCP 隧道本身的评价,这个话题我之前评论了很多:
https://blog.csdn.net/dog250/article/details/81257271
https://blog.csdn.net/dog250/article/details/106955747
为了获得一种既视感,接下来我来用一个实验验证上面的文字。
我做下面的测试拓扑:
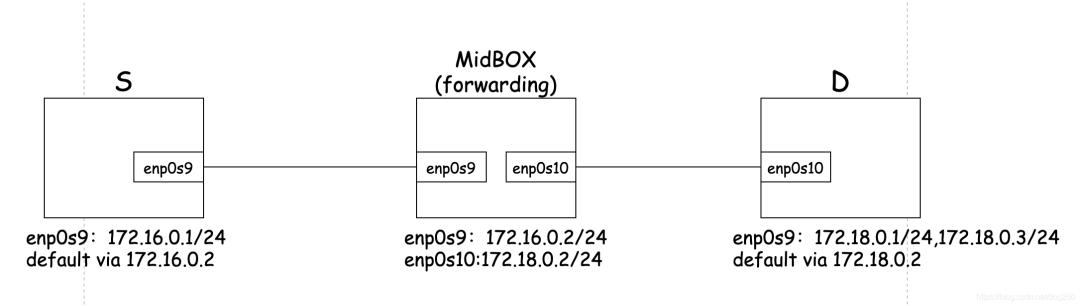
为了将一个模拟出来的长肥管道拆成两段,我构建了两条隧道,让测试的 TCP 流依次经过这两条隧道的封装。为了构建 TCP 隧道,我使用简单现成的 simpletun 来完成。
这里是我的 simpletun 版本:
https://github.com/marywangran/simpletun
正如 README 里的示例,其实没有必要为tun0配置 IP 地址的,但是给个 IP 地址思路更清晰,因此我的实验中均为 tun 设备指定了 IP 地址。下图是实验环境:
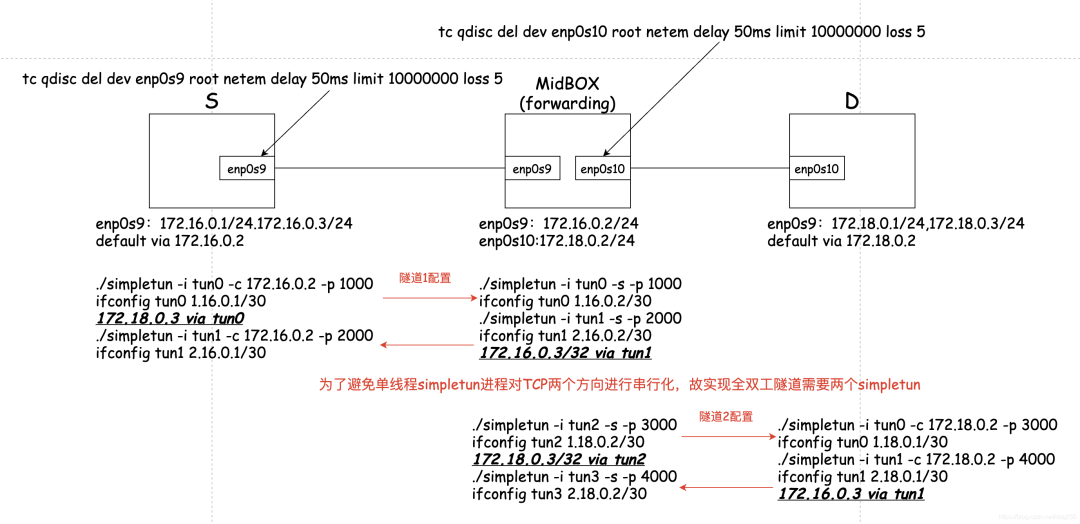
配置都写在图中了,下面是测试 case:
-
case1:测试 TCP 直接通过 S-D 长肥管道的吞吐。
-
case2:测试 TCP 从 S 经由隧道 T1,T2 到达 D 的吞吐。
下面是 case1 的测试。
D 上执行 iperf -s,S 上执行:
# 绑定 172.16.0.1iperf -c 172.18.0.1 -B 172.16.0.1 -i 1 -P 1 -t 15
结果摘要如下:
...[ 3] 9.0-10.0 sec 63.6 KBytes 521 Kbits/sec[ 3] 10.0-11.0 sec 63.6 KBytes 521 Kbits/sec[ 3] 11.0-12.0 sec 17.0 KBytes 139 Kbits/sec[ 3] 12.0-13.0 sec 63.6 KBytes 521 Kbits/sec[ 3] 13.0-14.0 sec 63.6 KBytes 521 Kbits/sec[ 3] 14.0-15.0 sec 80.6 KBytes 660 Kbits/sec[ 3] 0.0-15.2 sec 1.27 MBytes 699 Kbits/sec
下面是 case2 的测试。
D 上执行 iperf -s,S 上执行:
# 绑定 172.16.0.3iperf -c 172.18.0.3 -B 172.16.0.3 -i 1 -P 1 -t 15
结果摘要如下:
...[ 3] 9.0-10.0 sec 127 KBytes 1.04 Mbits/sec[ 3] 10.0-11.0 sec 445 KBytes 3.65 Mbits/sec[ 3] 11.0-12.0 sec 127 KBytes 1.04 Mbits/sec[ 3] 12.0-13.0 sec 382 KBytes 3.13 Mbits/sec[ 3] 13.0-14.0 sec 127 KBytes 1.04 Mbits/sec[ 3] 14.0-15.0 sec 90.5 KBytes 741 Kbits/sec[ 3] 0.0-15.2 sec 2.14 MBytes 1.18 Mbits/sec
结论显而易见,长路径拆分成短路径后,RTT 显然更小了,丢包感知,丢包恢复随之变得迅速。此外一条长肥管道得以以更小的段为单位分而治之,再也没有必要在全局使用同一个拥塞控制策略了。
分而治之非同质化的长肥管道, 这意味着什么?
这意味着,不同 TCP 隧道段根据所跨越链路的网络实际情况可以采用不同的拥塞控制算法: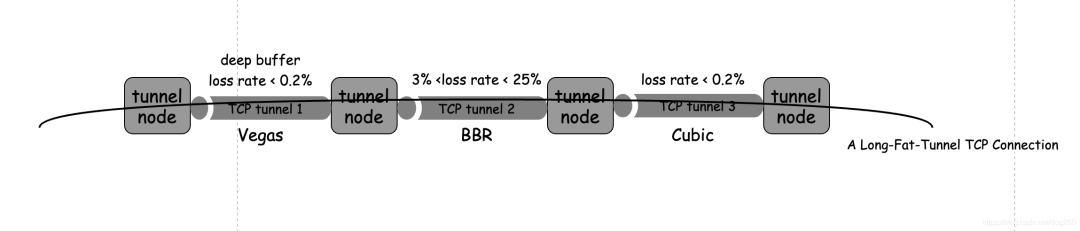
当我们的广域网用这种或者类似这种 Overlay 网络连接在一起的时候,我们有能力定义每一个小段的传输策略,这种细粒度的控制能力正是我们所需要的。
我们需要定义广域网,我们需要 SDWAN。

程序员如何避免陷入“内卷”、选择什么技术最有前景,中国开发者现状与技术趋势究竟是什么样?快来参与「2020 中国开发者大调查」,更有丰富奖品送不停!

☞任正非就注册姚安娜商标道歉;人人影视字幕组因盗版被查;JIRA、Confluence 等产品本月停售本地化版本 | 极客头条☞三年已投 1000 亿打造的达摩院,何以仗剑走天涯?☞Dropbox 的崛起之路,创始人曾拒绝乔布斯天价收购
☞一行代码没写,凭啥被尊为“第一位程序员”?

20年前,《新程序员》创刊时,我们的心愿是全面关注程序员成长,中国将拥有新一代世界级的程序员。20年后的今天,我们有了新的使命:助力中国IT技术人成长,成就一亿技术人!
更多推荐



 0
0 0
0- 0



 已为社区贡献12373条内容
已为社区贡献12373条内容

所有评论(0)