漫画:从打牌到 map-reduce 工作原理解析
作者 |channingbreeze责编 | 仲培艺小史是一个非科班的程序员,虽然学的是电子专业,但是通过自己的努力成功通过了面试,现在要开始迎接新生活了。生活现场找...


作者 | channingbreeze
责编 | 仲培艺
小史是一个非科班的程序员,虽然学的是电子专业,但是通过自己的努力成功通过了面试,现在要开始迎接新生活了。

生活现场

找到工作后的一小段时间是清闲的,小史把新租房收拾利索后,就开始找同学小赵、小李和小王来聚会了。
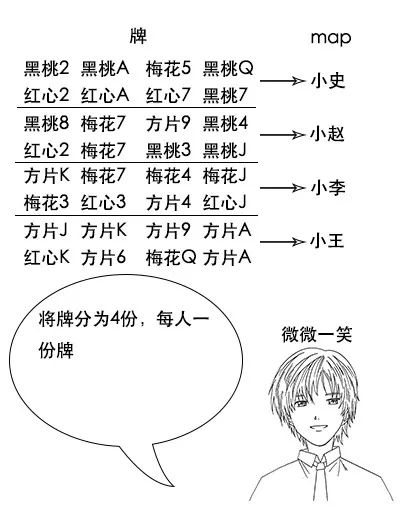
吃过午饭后,下午没事,四个人一起商量来打升级。打升级要两副扑克牌,小史就去找吕老师借牌去了。
【多几张牌】

吕老师给小史拿出一把牌。




【map-reduce】

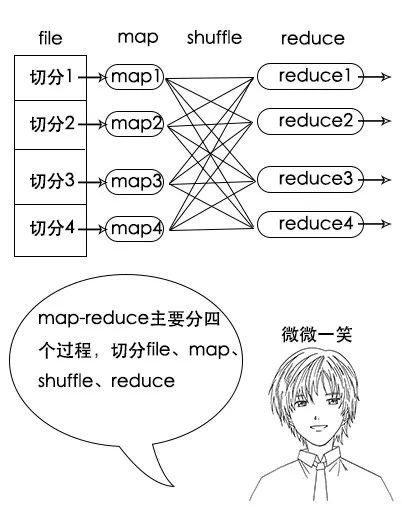







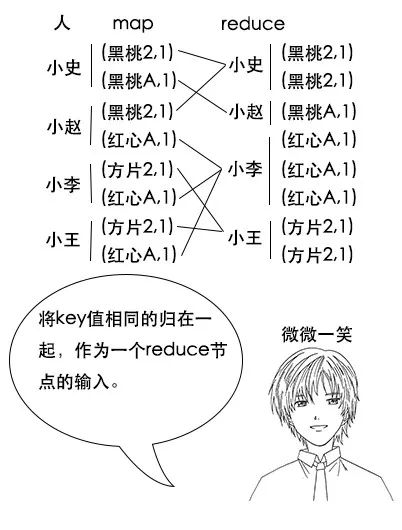



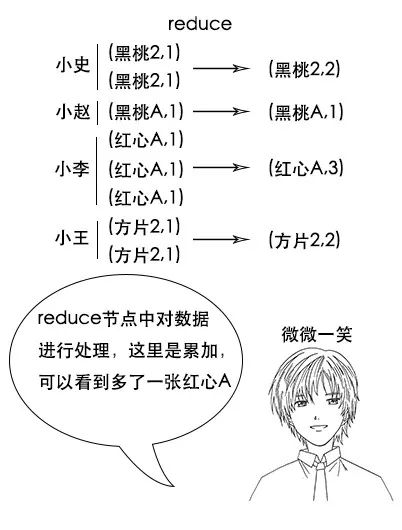
(注意,如果有两幅完整的牌,那么小赵手中的黑桃 A 一定不少于 2 张,因为其他人手中已经不可能有黑桃 A 了,图中的数据只是演示。)

【hadoop 中的 map-reduce】

吕老师:过程看上去很简单,但是要实现并不简单,要考虑很多异常情况,幸好开源项目 Hadoop 已经帮我们实现了这个模型,我们用它很简单就能实现 map-reduce。



吕老师:Hadoop 是一个分布式计算平台,我们只要开发 map-reduce 的作业(job),然后提交到 Hadoop 平台,它就会帮我们跑这个 map-reduce 的作业啦。


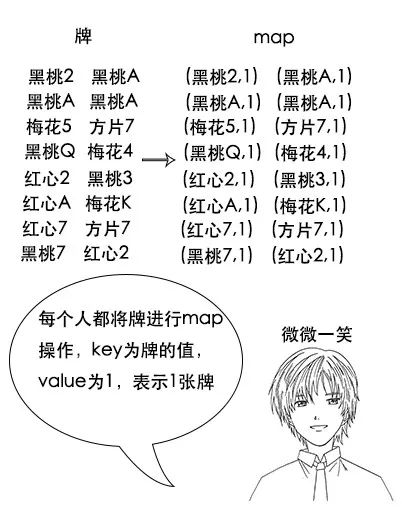
map 阶段:
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws java.io.IOException, InterruptedException {
String card = value.toString();
context.write(new Text(card), new LongWritable(1L));
};
}
(友情提示:可左右滑动)

吕老师:申明不用看,主要看 map 方法,它有三个参数,key、value 和 context,逻辑也很简单,其实就是用 context.write 往下游写了一个 (card,1) 的映射关系。
reduce 阶段:
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
protected void reduce(Text key, java.lang.Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws java.io.IOException, InterruptedException {
long count = 0L;
for (LongWritable value : values) {
count += value.get();
}
context.write(key, new LongWritable(count));
};
}
(友情提示:可左右滑动)
吕老师:reduce 也很简单,方法中三个参数,key、values 和 context,因为到了 reduce 阶段,一个 key 可能有多个 value,所以这里传进来的是 values,函数逻辑其实就是简单地将 values 累加,然后通过 context.write 输出。

小史:我明白了,Hadoop 其实把 map-reduce 的流程已经固定下来并且实现了,只留给我们自定义 map 和自定义 reduce 的接口,而这两部分恰好是和业务强相关的。

小史:也就是说业务方只需要告诉 Hadoop 怎么进行 map 和怎么进行 reduce,Hadoop 就能帮我们跑 map-reduce 的计算任务啦。
【分区函数】


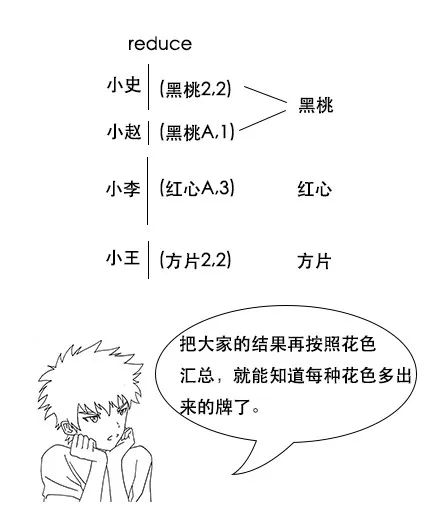



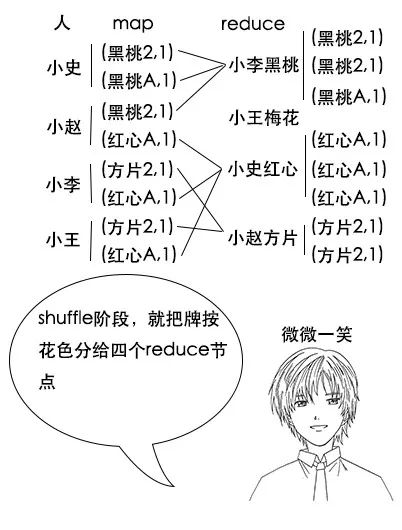

小史:我明白了,这样一来,最后 reduce 完成之后,我这边多出来的牌全是红心的,其他人多出来的牌也算是同一花色,就不用进行二次统计了,这真是个好办法。

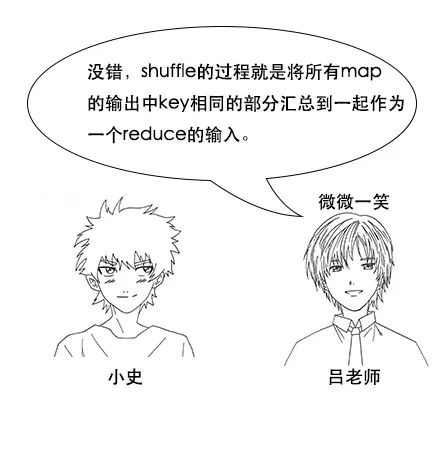
吕老师:没错,这就是分区函数的作用,在 Hadoop 中,虽然 shuffle 阶段有默认规则,但是我们可以自定义分区函数来改变这个规则,让它更加适合我们的业务。
【合并函数】





吕老师:如果你不合并,那么传给 shuffle 阶段的就有两个数据,如果你预合并了,那么传给 shuffle 阶段的就只有一个数据,这样数据量减少了一半。
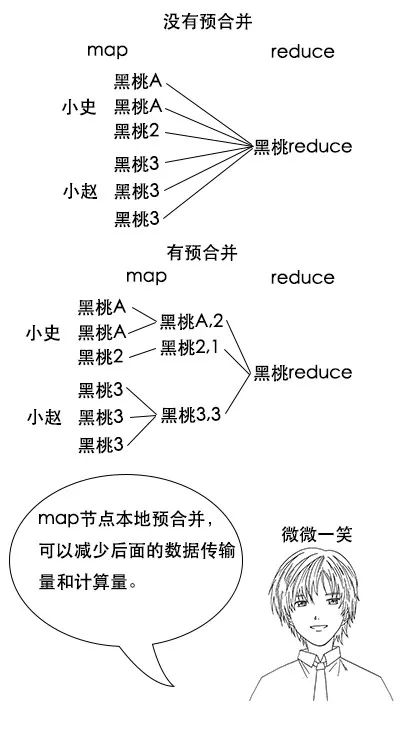




吕老师:Hadoop 当然考虑到了这个点,你可以自定义一个合并函数,Hadoop 在 map 阶段会调用它对本地数据进行预合并。

【hadoop帮我们做的事情】







吕老师:还有呀,刚才说的分布式系统中网络传输是有成本的,Hadoop 会帮我们把数据送到最近的节点,尽量减少网络传输。




吕老师:Hadoop 有两大重大贡献,一个是刚刚讲的 map-reduce,另一个是分布式文件系统 HDFS,HDFS 可以说是分布式存储系统的基石。其实一般来说,map-reduce 任务的输入,也就是那个很大的数据文件,一般都是存在 HDFS 上的。


总结
小史在往回走的路上,在手机里记录下了这次的笔记:
1. map-reduce 的四个关键阶段:file 切分、map 阶段、shuffle 阶段、reduce 阶段。
2. Hadoop 帮我们做了大部分工作,我们只需自定义 map 和 reduce 阶段。
3. 可以通过自定义分区函数和合并函数控制 map-reduce 过程的细节。
4. Hadoop 还有一个叫 HDFS 的牛逼东西,下次问问吕老师。
【回到房间】
作者:channingbreeze,国内某互联网公司全栈开发。
声明:本文为作者投稿,版权归对方所有。
热 文 推 荐
☞ 5G 兴起、智能手机饱和、AI 普及......2019 年的科技趋势预测
print_r('点个好看吧!');
var_dump('点个好看吧!');
NSLog(@"点个好看吧!");
System.out.println("点个好看吧!");
console.log("点个好看吧!");
print("点个好看吧!");
printf("点个好看吧!\n");
cout << "点个好看吧!" << endl;
Console.WriteLine("点个好看吧!");
fmt.Println("点个好看吧!");
Response.Write("点个好看吧!");
alert("点个好看吧!")
echo "点个好看吧!"
![]() 点击“阅读原文”,打开 CSDN App 阅读更贴心!
点击“阅读原文”,打开 CSDN App 阅读更贴心!
 喜欢就点击“好看”吧
喜欢就点击“好看”吧

20年前,《新程序员》创刊时,我们的心愿是全面关注程序员成长,中国将拥有新一代世界级的程序员。20年后的今天,我们有了新的使命:助力中国IT技术人成长,成就一亿技术人!
更多推荐



 6
6 0
0- 0



 已为社区贡献12387条内容
已为社区贡献12387条内容

所有评论(0)