来自未来的缓存 Caffeine,带你揭开它的神秘面纱
作者|Garnett来源| Garnett的Java之路(ID:gh_009246af52d4)头图 | CSDN下载自东方ICcaffeine是什么,它和redis什么区别,...


作者 | Garnett
来源 | Garnett的Java之路(ID:gh_009246af52d4)
头图 | CSDN 下载自东方IC
caffeine是什么,它和redis什么区别,有哪些作用,那么让我们带着疑问让Garnett来告诉你这个来自未来的缓存-Caffeine!

Caffeine和Redis的区别是什么?
1、相同点:
两个都是缓存的方式
2、不同点:
-
redis是将数据存储到内存里
caffeine是将数据存储在本地应用里 -
caffeine和redis相比,没有了网络IO上的消耗
3、联系:
一般将两者结合起来,形成一二级缓存。使用流程大致如下:
去一级缓存中查找数据(caffeine-本地应用内)
如果没有的话,去二级缓存中查找数据(redis-内存)
再没有,再去数据库中查找数据(数据库-磁盘)
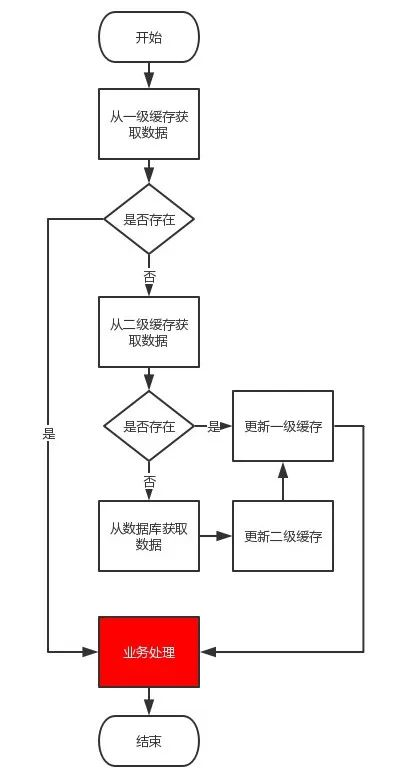
到这里大家应该清楚了其实redis和caffeine都是缓存,但是他们并不相同,所以别混淆了!

那么什么是 Caffeine
1、Caffeine简介
Caffeine是基于jdk 1.8 Version的高性能缓存库。Caffeine提供的内存缓存使用参考Google guava的API。Caffeine是基于Google Guava Cache设计经验上改进的成果。
Caffeine是使用jdk 1.8对Guava cache的重写版本,基于LRU算法实现,支持多种缓存过期策略。
那么先来看看Caffeine和其他的进程缓存的区别,为什么叫它来自未来的缓存呢?
2、其他进程缓存的简单介绍
Google Guava工具包中的一个非常方便易用的本地化缓存实现,基于LRU算法实现,支持多种缓存过期策略。
EhCache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的CacheProvider。
3、性能比较
场景1:8个线程读,100%的读操作

场景二:6个线程读,2个线程写,也就是75%的读操作,25%的写操作

场景三:8个线程写,100%的写操作

可以清楚的看到Caffeine效率明显的高于其他缓存。
4、如何使用
public static void main(String[] args) {
LoadingCache<String, String> build = CacheBuilder.newBuilder().initialCapacity(1).maximumSize(100).expireAfterWrite(1, TimeUnit.DAYS)
.build(new CacheLoader<String, String>() {
//默认的数据加载实现,当调用get取值的时候,如果key没有对应的值,就调用这个方法进行加载
@Override
public String load(String key) {
return "";
}
});
}
5、参数方法
-
initialCapacity(1) 初始缓存长度为1
-
maximumSize(100) 最大长度为100
-
expireAfterWrite(1, TimeUnit.DAYS) 设置缓存策略在1天未写入过期缓存
Caffeine的原理
1、W-TinyLFU
既然说到了淘汰策略,那么就简单说说redis的吧

继续说Caffeine的淘汰策略
传统的LFU受时间周期的影响比较大。所以各种LFU的变种出现了,基于时间周期进行衰减,或者在最近某个时间段内的频率。同样的LFU也会使用额外空间记录每一个数据访问的频率,即使数据没有在缓存中也需要记录,所以需要维护的额外空间很大。
可以试想我们对这个维护空间建立一个hashMap,每个数据项都会存在这个hashMap中,当数据量特别大的时候,这个hashMap也会特别大。
再回到LRU,我们的LRU也不是那么一无是处,LRU可以很好的应对突发流量的情况,因为他不需要累计数据频率。
所以W-TinyLFU结合了LRU和LFU,以及其他的算法的一些特点。
为了改进上述 LRU 和 LFU 存在的问题,前Google工程师在 TinyLfu的基础上发明了 W-TinyLFU 缓存算法。Caffine 就是基于此算法开发的。
Caffeine 因使用 Window TinyLfu 回收策略,提供了一个近乎最佳的命中率。
TinyLFU维护了近期访问记录的频率信息,作为一个过滤器,当新记录来时,只有满足TinyLFU要求的记录才可以被插入缓存。
TinyLFU借助了数据流Sketching技术,它可以用小得多的空间存放频次信息。TinyLFU采用了一种基于滑动窗口的时间衰减设计机制,借助于一种简易的 reset 操作:每次添加一条记录到Sketch的时候,都会给一个计数器上加 1,当计数器达到一个尺寸 W 的时候,把所有记录的 Sketch 数值都除以 2,该 reset 操作可以起到衰减的作用 。
W-TinyLFU主要用来解决一些稀疏的突发访问元素。在一些数目很少但突发访问量很大的场景下,TinyLFU将无法保存这类元素,因为它们无法在给定时间内积累到足够高的频率。因此 W-TinyLFU 就是结合 LFU 和LRU,前者用来应对大多数场景,而 LRU 用来处理突发流量。
在处理频次记录方面,采用 Bloom Filter,对于每个key,用 n 个 byte 每个存储一个标志用来判断 key 是否在集合中。原理就是使用 k 个 hash 函数来将 key 散列成一个整数。
在 W-TinyLFU 中使用 Count-Min Sketch 记录 key 的访问频次,而它就是布隆过滤器的一个变种。
2、读写性能
在guava cache中我们说过其读写操作中夹杂着过期时间的处理,也就是你在一次Put操作中有可能还会做淘汰操作,所以其读写性能会受到一定影响,可以看上面的图中,caffeine的确在读写操作上面完爆guava cache。主要是因为在caffeine,对这些事件的操作是通过异步操作,他将事件提交至队列,这里的队列的数据结构是RingBuffer。然后会通过默认的ForkJoinPool.commonPool(),或者自己配置线程池,进行取队列操作,然后在进行后续的淘汰,过期操作。
当然读写也是有不同的队列,在caffeine中认为缓存读比写多很多,所以对于写操作是所有线程共享一个Ringbuffer。
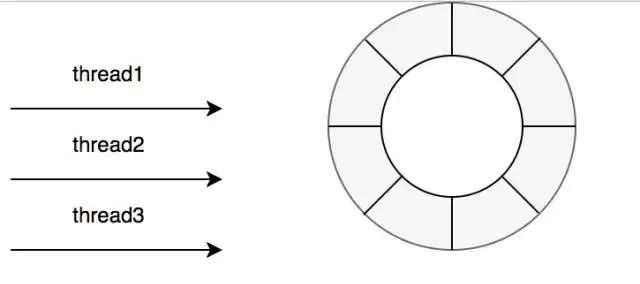
对于读操作比写操作更加频繁,进一步减少竞争,其为每个线程配备了一个RingBuffer:

3、数据淘汰策略
在caffeine所有的数据都在ConcurrentHashMap中,这个和guava cache不同,guava cache是自己实现了个类似ConcurrentHashMap的结构。在caffeine中有三个记录引用的LRU队列:
-
Eden队列:在caffeine中规定只能为缓存容量的%1,如果size=100,那这个队列的有效大小就等于1。这个队列中记录的是新到的数据,防止突发流量由于之前没有访问频率,而导致被淘汰。比如有一部新剧上线,在最开始其实是没有访问频率的,防止上线之后被其他缓存淘汰出去,而加入这个区域。伊甸区,最舒服最安逸的区域,在这里很难被其他数据淘汰。
-
Probation队列:叫做缓刑队列,在这个队列就代表你的数据相对比较冷,马上就要被淘汰了。这个有效大小为size减去eden减去protected。
-
Protected队列:在这个队列中,可以稍微放心一下了,你暂时不会被淘汰,但是别急,如果Probation队列没有数据了或者Protected数据满了,你也将会被面临淘汰的尴尬局面。当然想要变成这个队列,需要把Probation访问一次之后,就会提升为Protected队列。这个有效大小为(size减去eden) X 80% 如果size =100,就会是79。
这三个队列关系如下:

-
所有的新数据都会进入Eden。
-
Eden满了,淘汰进入Probation。
-
如果在Probation中访问了其中某个数据,则这个数据升级为Protected。
-
如果Protected满了又会继续降级为Probation。
对于发生数据淘汰的时候,会从Probation中进行淘汰。会把这个队列中的数据队头称为受害者,这个队头肯定是最早进入的,按照LRU队列的算法的话那他其实他就应该被淘汰,但是在这里只能叫他受害者,这个队列是缓刑队列,代表马上要给他行刑了。这里会取出队尾叫候选者,也叫攻击者。这里受害者会和攻击者PK决出我们应该被淘汰的。
通过我们的Count-Min Sketch中的记录的频率数据有以下几个判断:
-
如果攻击者大于受害者,那么受害者就直接被淘汰。
-
如果攻击者<=5,那么直接淘汰攻击者。这个逻辑在他的注释中有解释:

他认为设置一个预热的门槛会让整体命中率更高。
-
其他情况,随机淘汰。
Caffeine功能剖析
1、转瞬即逝-过期策略
在Caffeine中分为两种缓存,一个是有界缓存,一个是无界缓存,无界缓存不需要过期并且没有界限。在有界缓存中提供了三个过期API:
-
expireAfterWrite:代表着写了之后多久过期。(上面列子就是这种方式)
-
expireAfterAccess:代表着最后一次访问了之后多久过期。
-
expireAfter:在expireAfter中需要自己实现Expiry接口,这个接口支持create,update,以及access了之后多久过期。注意这个API和前面两个API是互斥的。这里和前面两个API不同的是,需要你告诉缓存框架,他应该在具体的某个时间过期,也就是通过前面的重写create,update,以及access的方法,获取具体的过期时间。
2、除旧布新-更新策略
何为更新策略?就是在设定多长时间后会自动刷新缓存。
Caffeine提供了refreshAfterWrite()方法来让我们进行写后多久更新策略:
LoadingCache<String, String> build = CacheBuilder.newBuilder().refreshAfterWrite(1, TimeUnit.DAYS)
.build(new CacheLoader<String, String>() {
@Override
public String load(String key) {
return "";
}
});
}
上面的代码我们需要建立一个CacheLodaer来进行刷新,这里是同步进行的,可以通过buildAsync方法进行异步构建。在实际业务中这里可以把我们代码中的mapper传入进去,进行数据源的刷新。
但是实际使用中,你设置了一天刷新,但是一天后你发现缓存并没有刷新。这是因为必有在1天后这个缓存再次访问才能刷新,如果没人访问,那么永远也不会刷新。你明白了吗?
我们来看看自动刷新他是怎么做的呢?自动刷新只存在读操作之后,也就是我们afterRead()这个方法,其中有个方法叫refreshIfNeeded,他会根据你是同步还是异步然后进行刷新处理。
3、知己知彼-打点监控
在Caffeine中提供了一些的打点监控策略,通过recordStats()Api进行开启,默认是使用Caffeine自带的,也可以自己进行实现。在StatsCounter接口中,定义了需要打点的方法目前来说有如下几个:
-
recordHits:记录缓存命中
-
recordMisses:记录缓存未命中
-
recordLoadSuccess:记录加载成功(指的是CacheLoader加载成功)
-
recordLoadFailure:记录加载失败
-
recordEviction:记录淘汰数据
通过上面的监听,我们可以实时监控缓存当前的状态,以评估缓存的健康程度以及缓存命中率等,方便后续调整参数。
4、有始有终-淘汰监听
有很多时候我们需要知道Caffeine中的缓存为什么被淘汰了呢,从而进行一些优化?这个时候我们就需要一个监听器,代码如下所示:
Cache<String,String> cache = Caffeine.newBuilder()
.removaListener(((key,value,cause) -> {
System.out.println(cause); }))
.build();
在Caffeine中被淘汰的原因有很多种:
-
EXPLICIT: 这个原因是,用户造成的,通过调用remove方法从而进行删除。
-
REPLACED: 更新的时候,其实相当于把老的value给删了。
-
COLLECTED: 用于我们的垃圾收集器,也就是我们上面减少的软引用,弱引用。
-
EXPIRED:过期淘汰。
-
SIZE: 大小淘汰,当超过最大的时候就会进行淘汰。
当我们进行淘汰的时候就会进行回调,我们可以打印出日志,对数据淘汰进行实时监控。


更多精彩推荐
☞苹果M1芯片:如何开启一个时代
☞PHP 还有未来么,还是 25 岁就“寿终正寝”了?
☞Julia 创始人访谈:简单机器学习任务可与 Python 媲美,复杂任务胜过 Python
☞深度揭秘垃圾回收底层,这次让你彻底弄懂它
☞别再问如何用 Python 提取 PDF 内容了!
☞偷盖茨、奥巴马 Twitter 的黑客被抓了,年轻到你想不到!
点分享点点赞点在看

20年前,《新程序员》创刊时,我们的心愿是全面关注程序员成长,中国将拥有新一代世界级的程序员。20年后的今天,我们有了新的使命:助力中国IT技术人成长,成就一亿技术人!
更多推荐



 0
0 0
0- 0



 已为社区贡献12380条内容
已为社区贡献12380条内容

所有评论(0)